Merge branch 'main' into patch-2
5
.vscode/settings.json
vendored
Normal file
@ -0,0 +1,5 @@
|
||||
{
|
||||
"githubPullRequests.ignoredPullRequestBranches": [
|
||||
"main"
|
||||
]
|
||||
}
|
||||
@ -179,7 +179,7 @@ Following [Module 09a](https://microsoftlearning.github.io/AZ-104-MicrosoftAzure
|
||||
|
||||
- Task 6: Configure and test autoscaling of the Azure web app
|
||||
|
||||
This script I am using can be found in (Cloud/05Serverless)
|
||||
This script I am using can be found in (Cloud/04Serverless)
|
||||
|
||||

|
||||
|
||||
|
||||
6
2023.md
@ -156,9 +156,9 @@ Or contact us via Twitter, my handle is [@MichaelCade1](https://twitter.com/Mich
|
||||
|
||||
### Engineering for Day 2 Ops
|
||||
|
||||
- [] 👷🏻♀️ 84 > [](2023/day84.md)
|
||||
- [] 👷🏻♀️ 85 > [](2023/day85.md)
|
||||
- [] 👷🏻♀️ 86 > [](2023/day86.md)
|
||||
- [] 👷🏻♀️ 84 > [Writing an API - What is an API?](2023/day84.md)
|
||||
- [] 👷🏻♀️ 85 > [Queues, Queue workers and Tasks (Asynchronous architecture)](2023/day85.md)
|
||||
- [] 👷🏻♀️ 86 > [Designing for Resilience, Redundancy and Reliability](2023/day86.md)
|
||||
- [] 👷🏻♀️ 87 > [](2023/day87.md)
|
||||
- [] 👷🏻♀️ 88 > [](2023/day88.md)
|
||||
- [] 👷🏻♀️ 89 > [](2023/day89.md)
|
||||
|
||||
@ -81,4 +81,5 @@ Also please add any additional resources.
|
||||
- [Introducing the InfoSec colour wheel — blending developers with red and blue security teams.](https://hackernoon.com/introducing-the-infosec-colour-wheel-blending-developers-with-red-and-blue-security-teams-6437c1a07700)
|
||||
|
||||
|
||||
See you on [Day 5](day05.md)
|
||||
See you on [Day 5](day05.md).
|
||||
|
||||
|
||||
@ -53,3 +53,4 @@ The reason I am raising this is that security never stops, the growth of Open-So
|
||||
- [IBM - The 3 A's of Open Source Security](https://www.youtube.com/watch?v=baZH6CX6Zno)
|
||||
- [Log4j (CVE-2021-44228) RCE Vulnerability Explained](https://www.youtube.com/watch?v=0-abhd-CLwQ)
|
||||
|
||||
See you on [Day 6](day06.md).
|
||||
|
||||
@ -92,3 +92,5 @@ It contains the example I used in this article + a fuzz test that triggers a fai
|
||||
- <https://en.wikipedia.org/wiki/Fuzzing>
|
||||
- [Fuzzing in Go by Valentin Deleplace, Devoxx Belgium 2022](https://www.youtube.com/watch?v=Zlf3s4EjnFU)
|
||||
- [Write applications faster and securely with Go by Cody Oss, Go Day 2022](https://www.youtube.com/watch?v=aw7lFSFGKZs)
|
||||
|
||||
See you on [Day 17](day17.md).
|
||||
|
||||
@ -240,3 +240,5 @@ There are many tools that can help us in fuzzy testing our web applications, bot
|
||||
[Fuzzing Session: Finding Bugs and Vulnerabilities Automatically](https://youtu.be/DSJePjhBN5E)
|
||||
|
||||
[Fuzzing the CNCF Landscape](https://youtu.be/zIyIZxAZLzo)
|
||||
|
||||
See you on [Day 18](day18.md).
|
||||
|
||||
@ -24,3 +24,5 @@ As with all other tools part of DevSecOps pipeline DAST should not be the only s
|
||||
- https://github.com/zaproxy/zaproxy
|
||||
- https://www.arachni-scanner.com/
|
||||
- https://owasp.org/www-project-devsecops-guideline/latest/02b-Dynamic-Application-Security-Testing
|
||||
|
||||
See you on [Day 19](day19.md).
|
||||
|
||||
@ -6,21 +6,26 @@ IAST works through software instrumentation, or the use of instruments to monito
|
||||
IAST agent is running inside the application and monitoring for known attack patterns. As it is part of the application, it can monitor traffic between different components (either as classic MVC deployments and in microservices deployment).
|
||||
|
||||
## For IAST to be used, there are few prerequisites.
|
||||
|
||||
- Application should be instrumented (inject the agent).
|
||||
- Traffic should be generated - via manual or automated tests. Another possible approach is via DAST tools (OWASP ZAP can be used for example).
|
||||
|
||||
## Advantages
|
||||
|
||||
One of the main advantages of IAST tools is that they can provide detailed and accurate information about vulnerabilities and how to fix them. This can save developers a lot of time and effort, as they don't have to manually search for vulnerabilities or try to reproduce them in a testing environment. IAST tools can also identify vulnerabilities that might be missed by other testing methods, such as those that require user interaction or are triggered under certain conditions. Testing time depends on the tests used (as IAST is not a standalone system) and with faster tests (automated tests) can be included into CI/CD pipelines. It can be used to detect different kind of vulnerabilities and due to the nature of the tools (it looks for “real traffic only) false positives/negatives findings are relatively rear compared to other testing types.
|
||||
IAST can be used in two flavours - as a typical testing tool and as real-time protection (it is called RAST in this case). Both work at the same principles and can be used together.
|
||||
|
||||
## There are several disadvantages of the technology as well:
|
||||
|
||||
- It is relatively new technology so there is not a lot of knowledge and experience both for the security teams and for the tools builders (open-source or commercial).
|
||||
- The solution cannot be used alone - something (or someone) should generate traffic patterns. It is important that all possible endpoints are queried during the tests.
|
||||
- Findings are based on traffic. This is especially true if used for testing alone - if there is no traffic to a portion of the app / site it would not be tested so no findings are going to be generated.
|
||||
- Due to need of instrumentation of the app, it can be fairly complex, especially compared to the source scanning tools (SAST or SCA).
|
||||
|
||||
There are several different IAST tools available, each with its own features and capabilities.
|
||||
|
||||
## Some common features of IAST tools include:
|
||||
|
||||
- Real-time monitoring: IAST tools monitor the application's behaviour in real-time, allowing them to identify vulnerabilities as they occur.
|
||||
- Vulnerability identification: IAST tools can identify a wide range of vulnerabilities, including injection attacks, cross-site scripting (XSS), and cross-site request forgery (CSRF).
|
||||
- Remediation guidance: IAST tools often provide detailed information about how to fix identified vulnerabilities, including code snippets and recommendations for secure coding practices.
|
||||
@ -29,5 +34,8 @@ There are several different IAST tools available, each with its own features and
|
||||
IAST tools can be a valuable addition to a developer's toolkit, as they can help identify and fix vulnerabilities in real-time, saving time and effort. If you are a developer and are interested in using an IAST tool, there are many options available, so it is important to research and compare different tools to find the one that best fits your needs.
|
||||
|
||||
## Tool example
|
||||
|
||||
There are almost no open-source tools on the market. Example is the commercial tool: Contrast Community Edition (CE) - Fully featured version for 1 app and up to 5 users (some Enterprise features disabled). Contrast CE supports Java and .NET only.
|
||||
Can be found here - https://www.contrastsecurity.com/contrast-community-edition
|
||||
|
||||
See you on [Day 20](day20.md).
|
||||
|
||||
44
2023/day2-ops-code/README.md
Normal file
@ -0,0 +1,44 @@
|
||||
# Getting started
|
||||
|
||||
This repo expects you to have a working kubernetes cluster already setup and
|
||||
available with kubectl
|
||||
|
||||
We expect you already have a kubernetes cluster setup and available with kubectl and helm.
|
||||
|
||||
I like using (Civo)[https://www.civo.com/] for this as it is easy to setup and run clusters
|
||||
|
||||
The code is available in this folder to build/push your own images if you wish - there are no instructions for this.
|
||||
|
||||
## Start the Database
|
||||
```shell
|
||||
kubectl apply -f database/mysql.yaml
|
||||
```
|
||||
|
||||
|
||||
## deploy the day1 - sync
|
||||
```shell
|
||||
kubectl apply -f synchronous/k8s.yaml
|
||||
```
|
||||
|
||||
Check your logs
|
||||
```shell
|
||||
kubectl logs deploy/generator
|
||||
|
||||
kubectl logs deploy/requestor
|
||||
```
|
||||
|
||||
## deploy nats
|
||||
helm repo add nats https://nats-io.github.io/k8s/helm/charts/
|
||||
helm install my-nats nats/nats
|
||||
|
||||
## deploy day 2 - async
|
||||
```shell
|
||||
kubectl apply -f async/k8s.yaml
|
||||
```
|
||||
|
||||
Check your logs
|
||||
```shell
|
||||
kubectl logs deploy/generator
|
||||
|
||||
kubectl logs deploy/requestor
|
||||
```
|
||||
17
2023/day2-ops-code/async/generator/Dockerfile
Normal file
@ -0,0 +1,17 @@
|
||||
# Set the base image to use
|
||||
FROM golang:1.17-alpine
|
||||
|
||||
# Set the working directory inside the container
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the source code into the container
|
||||
COPY . .
|
||||
|
||||
# Build the Go application
|
||||
RUN go build -o main .
|
||||
|
||||
# Expose the port that the application will run on
|
||||
EXPOSE 8080
|
||||
|
||||
# Define the command that will run when the container starts
|
||||
CMD ["/app/main"]
|
||||
17
2023/day2-ops-code/async/generator/go.mod
Normal file
@ -0,0 +1,17 @@
|
||||
module main
|
||||
|
||||
go 1.20
|
||||
|
||||
require (
|
||||
github.com/go-sql-driver/mysql v1.7.0
|
||||
github.com/nats-io/nats.go v1.24.0
|
||||
)
|
||||
|
||||
require (
|
||||
github.com/golang/protobuf v1.5.3 // indirect
|
||||
github.com/nats-io/nats-server/v2 v2.9.15 // indirect
|
||||
github.com/nats-io/nkeys v0.3.0 // indirect
|
||||
github.com/nats-io/nuid v1.0.1 // indirect
|
||||
golang.org/x/crypto v0.6.0 // indirect
|
||||
google.golang.org/protobuf v1.30.0 // indirect
|
||||
)
|
||||
32
2023/day2-ops-code/async/generator/go.sum
Normal file
@ -0,0 +1,32 @@
|
||||
github.com/go-sql-driver/mysql v1.7.0 h1:ueSltNNllEqE3qcWBTD0iQd3IpL/6U+mJxLkazJ7YPc=
|
||||
github.com/go-sql-driver/mysql v1.7.0/go.mod h1:OXbVy3sEdcQ2Doequ6Z5BW6fXNQTmx+9S1MCJN5yJMI=
|
||||
github.com/golang/protobuf v1.5.0/go.mod h1:FsONVRAS9T7sI+LIUmWTfcYkHO4aIWwzhcaSAoJOfIk=
|
||||
github.com/golang/protobuf v1.5.3 h1:KhyjKVUg7Usr/dYsdSqoFveMYd5ko72D+zANwlG1mmg=
|
||||
github.com/golang/protobuf v1.5.3/go.mod h1:XVQd3VNwM+JqD3oG2Ue2ip4fOMUkwXdXDdiuN0vRsmY=
|
||||
github.com/google/go-cmp v0.5.5/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
|
||||
github.com/klauspost/compress v1.16.0 h1:iULayQNOReoYUe+1qtKOqw9CwJv3aNQu8ivo7lw1HU4=
|
||||
github.com/minio/highwayhash v1.0.2 h1:Aak5U0nElisjDCfPSG79Tgzkn2gl66NxOMspRrKnA/g=
|
||||
github.com/nats-io/jwt/v2 v2.3.0 h1:z2mA1a7tIf5ShggOFlR1oBPgd6hGqcDYsISxZByUzdI=
|
||||
github.com/nats-io/nats-server/v2 v2.9.15 h1:MuwEJheIwpvFgqvbs20W8Ish2azcygjf4Z0liVu2I4c=
|
||||
github.com/nats-io/nats-server/v2 v2.9.15/go.mod h1:QlCTy115fqpx4KSOPFIxSV7DdI6OxtZsGOL1JLdeRlE=
|
||||
github.com/nats-io/nats.go v1.24.0 h1:CRiD8L5GOQu/DcfkmgBcTTIQORMwizF+rPk6T0RaHVQ=
|
||||
github.com/nats-io/nats.go v1.24.0/go.mod h1:dVQF+BK3SzUZpwyzHedXsvH3EO38aVKuOPkkHlv5hXA=
|
||||
github.com/nats-io/nkeys v0.3.0 h1:cgM5tL53EvYRU+2YLXIK0G2mJtK12Ft9oeooSZMA2G8=
|
||||
github.com/nats-io/nkeys v0.3.0/go.mod h1:gvUNGjVcM2IPr5rCsRsC6Wb3Hr2CQAm08dsxtV6A5y4=
|
||||
github.com/nats-io/nuid v1.0.1 h1:5iA8DT8V7q8WK2EScv2padNa/rTESc1KdnPw4TC2paw=
|
||||
github.com/nats-io/nuid v1.0.1/go.mod h1:19wcPz3Ph3q0Jbyiqsd0kePYG7A95tJPxeL+1OSON2c=
|
||||
golang.org/x/crypto v0.0.0-20210314154223-e6e6c4f2bb5b/go.mod h1:T9bdIzuCu7OtxOm1hfPfRQxPLYneinmdGuTeoZ9dtd4=
|
||||
golang.org/x/crypto v0.6.0 h1:qfktjS5LUO+fFKeJXZ+ikTRijMmljikvG68fpMMruSc=
|
||||
golang.org/x/crypto v0.6.0/go.mod h1:OFC/31mSvZgRz0V1QTNCzfAI1aIRzbiufJtkMIlEp58=
|
||||
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.5.0 h1:MUK/U/4lj1t1oPg0HfuXDN/Z1wv31ZJ/YcPiGccS4DU=
|
||||
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/time v0.3.0 h1:rg5rLMjNzMS1RkNLzCG38eapWhnYLFYXDXj2gOlr8j4=
|
||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||
golang.org/x/xerrors v0.0.0-20191204190536-9bdfabe68543/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||
google.golang.org/protobuf v1.26.0-rc.1/go.mod h1:jlhhOSvTdKEhbULTjvd4ARK9grFBp09yW+WbY/TyQbw=
|
||||
google.golang.org/protobuf v1.26.0/go.mod h1:9q0QmTI4eRPtz6boOQmLYwt+qCgq0jsYwAQnmE0givc=
|
||||
google.golang.org/protobuf v1.30.0 h1:kPPoIgf3TsEvrm0PFe15JQ+570QVxYzEvvHqChK+cng=
|
||||
google.golang.org/protobuf v1.30.0/go.mod h1:HV8QOd/L58Z+nl8r43ehVNZIU/HEI6OcFqwMG9pJV4I=
|
||||
100
2023/day2-ops-code/async/generator/main.go
Normal file
@ -0,0 +1,100 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"database/sql"
|
||||
"fmt"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
nats "github.com/nats-io/nats.go"
|
||||
"math/rand"
|
||||
"time"
|
||||
)
|
||||
|
||||
func generateAndStoreString() (string, error) {
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// Generate a random string
|
||||
// Define a string of characters to use
|
||||
characters := "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
|
||||
|
||||
// Generate a random string of length 10
|
||||
randomString := make([]byte, 64)
|
||||
for i := range randomString {
|
||||
randomString[i] = characters[rand.Intn(len(characters))]
|
||||
}
|
||||
|
||||
// Insert the random number into the database
|
||||
_, err = db.Exec("INSERT INTO generator_async(random_string) VALUES(?)", string(randomString))
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
fmt.Printf("Random string %s has been inserted into the database\n", string(randomString))
|
||||
return string(randomString), nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
err := createGeneratordb()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
|
||||
nc, _ := nats.Connect("nats://my-nats:4222")
|
||||
defer nc.Close()
|
||||
|
||||
nc.Subscribe("generator", func(msg *nats.Msg) {
|
||||
s, err := generateAndStoreString()
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
nc.Publish("generator_reply", []byte(s))
|
||||
nc.Publish("confirmation", []byte(s))
|
||||
})
|
||||
|
||||
nc.Subscribe("confirmation_reply", func(msg *nats.Msg) {
|
||||
stringReceived(string(msg.Data))
|
||||
})
|
||||
// Subscribe to the queue
|
||||
// when a message comes in call generateAndStoreString() then put the string on the
|
||||
// reply queue. also add a message onto the confirmation queue
|
||||
|
||||
// subscribe to the confirmation reply queue
|
||||
// when a message comes in call
|
||||
|
||||
for {
|
||||
time.Sleep(1 * time.Second)
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func createGeneratordb() error {
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// try to create a table for us
|
||||
_, err = db.Exec("CREATE TABLE IF NOT EXISTS generator_async(random_string VARCHAR(100), seen BOOLEAN, requested BOOLEAN)")
|
||||
|
||||
return err
|
||||
}
|
||||
|
||||
func stringReceived(input string) {
|
||||
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
_, err = db.Exec("UPDATE generator_async SET requested = true WHERE random_string = ?", input)
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
}
|
||||
69
2023/day2-ops-code/async/k8s.yaml
Normal file
@ -0,0 +1,69 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: requestor
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: requestor
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: requestor
|
||||
spec:
|
||||
containers:
|
||||
- name: requestor
|
||||
image: heyal/requestor:async
|
||||
imagePullPolicy: Always
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: requestor-service
|
||||
spec:
|
||||
selector:
|
||||
app: requestor
|
||||
ports:
|
||||
- name: http
|
||||
protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: generator
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: generator
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: generator
|
||||
spec:
|
||||
containers:
|
||||
- name: generator
|
||||
image: heyal/generator:async
|
||||
imagePullPolicy: Always
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: generator-service
|
||||
spec:
|
||||
selector:
|
||||
app: generator
|
||||
ports:
|
||||
- name: http
|
||||
protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
type: ClusterIP
|
||||
17
2023/day2-ops-code/async/requestor/Dockerfile
Normal file
@ -0,0 +1,17 @@
|
||||
# Set the base image to use
|
||||
FROM golang:1.17-alpine
|
||||
|
||||
# Set the working directory inside the container
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the source code into the container
|
||||
COPY . .
|
||||
|
||||
# Build the Go application
|
||||
RUN go build -o main .
|
||||
|
||||
# Expose the port that the application will run on
|
||||
EXPOSE 8080
|
||||
|
||||
# Define the command that will run when the container starts
|
||||
CMD ["/app/main"]
|
||||
17
2023/day2-ops-code/async/requestor/go.mod
Normal file
@ -0,0 +1,17 @@
|
||||
module main
|
||||
|
||||
go 1.20
|
||||
|
||||
require (
|
||||
github.com/go-sql-driver/mysql v1.7.0
|
||||
github.com/nats-io/nats.go v1.24.0
|
||||
)
|
||||
|
||||
require (
|
||||
github.com/golang/protobuf v1.5.3 // indirect
|
||||
github.com/nats-io/nats-server/v2 v2.9.15 // indirect
|
||||
github.com/nats-io/nkeys v0.3.0 // indirect
|
||||
github.com/nats-io/nuid v1.0.1 // indirect
|
||||
golang.org/x/crypto v0.6.0 // indirect
|
||||
google.golang.org/protobuf v1.30.0 // indirect
|
||||
)
|
||||
32
2023/day2-ops-code/async/requestor/go.sum
Normal file
@ -0,0 +1,32 @@
|
||||
github.com/go-sql-driver/mysql v1.7.0 h1:ueSltNNllEqE3qcWBTD0iQd3IpL/6U+mJxLkazJ7YPc=
|
||||
github.com/go-sql-driver/mysql v1.7.0/go.mod h1:OXbVy3sEdcQ2Doequ6Z5BW6fXNQTmx+9S1MCJN5yJMI=
|
||||
github.com/golang/protobuf v1.5.0/go.mod h1:FsONVRAS9T7sI+LIUmWTfcYkHO4aIWwzhcaSAoJOfIk=
|
||||
github.com/golang/protobuf v1.5.3 h1:KhyjKVUg7Usr/dYsdSqoFveMYd5ko72D+zANwlG1mmg=
|
||||
github.com/golang/protobuf v1.5.3/go.mod h1:XVQd3VNwM+JqD3oG2Ue2ip4fOMUkwXdXDdiuN0vRsmY=
|
||||
github.com/google/go-cmp v0.5.5/go.mod h1:v8dTdLbMG2kIc/vJvl+f65V22dbkXbowE6jgT/gNBxE=
|
||||
github.com/klauspost/compress v1.16.0 h1:iULayQNOReoYUe+1qtKOqw9CwJv3aNQu8ivo7lw1HU4=
|
||||
github.com/minio/highwayhash v1.0.2 h1:Aak5U0nElisjDCfPSG79Tgzkn2gl66NxOMspRrKnA/g=
|
||||
github.com/nats-io/jwt/v2 v2.3.0 h1:z2mA1a7tIf5ShggOFlR1oBPgd6hGqcDYsISxZByUzdI=
|
||||
github.com/nats-io/nats-server/v2 v2.9.15 h1:MuwEJheIwpvFgqvbs20W8Ish2azcygjf4Z0liVu2I4c=
|
||||
github.com/nats-io/nats-server/v2 v2.9.15/go.mod h1:QlCTy115fqpx4KSOPFIxSV7DdI6OxtZsGOL1JLdeRlE=
|
||||
github.com/nats-io/nats.go v1.24.0 h1:CRiD8L5GOQu/DcfkmgBcTTIQORMwizF+rPk6T0RaHVQ=
|
||||
github.com/nats-io/nats.go v1.24.0/go.mod h1:dVQF+BK3SzUZpwyzHedXsvH3EO38aVKuOPkkHlv5hXA=
|
||||
github.com/nats-io/nkeys v0.3.0 h1:cgM5tL53EvYRU+2YLXIK0G2mJtK12Ft9oeooSZMA2G8=
|
||||
github.com/nats-io/nkeys v0.3.0/go.mod h1:gvUNGjVcM2IPr5rCsRsC6Wb3Hr2CQAm08dsxtV6A5y4=
|
||||
github.com/nats-io/nuid v1.0.1 h1:5iA8DT8V7q8WK2EScv2padNa/rTESc1KdnPw4TC2paw=
|
||||
github.com/nats-io/nuid v1.0.1/go.mod h1:19wcPz3Ph3q0Jbyiqsd0kePYG7A95tJPxeL+1OSON2c=
|
||||
golang.org/x/crypto v0.0.0-20210314154223-e6e6c4f2bb5b/go.mod h1:T9bdIzuCu7OtxOm1hfPfRQxPLYneinmdGuTeoZ9dtd4=
|
||||
golang.org/x/crypto v0.6.0 h1:qfktjS5LUO+fFKeJXZ+ikTRijMmljikvG68fpMMruSc=
|
||||
golang.org/x/crypto v0.6.0/go.mod h1:OFC/31mSvZgRz0V1QTNCzfAI1aIRzbiufJtkMIlEp58=
|
||||
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.5.0 h1:MUK/U/4lj1t1oPg0HfuXDN/Z1wv31ZJ/YcPiGccS4DU=
|
||||
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/time v0.3.0 h1:rg5rLMjNzMS1RkNLzCG38eapWhnYLFYXDXj2gOlr8j4=
|
||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||
golang.org/x/xerrors v0.0.0-20191204190536-9bdfabe68543/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||
google.golang.org/protobuf v1.26.0-rc.1/go.mod h1:jlhhOSvTdKEhbULTjvd4ARK9grFBp09yW+WbY/TyQbw=
|
||||
google.golang.org/protobuf v1.26.0/go.mod h1:9q0QmTI4eRPtz6boOQmLYwt+qCgq0jsYwAQnmE0givc=
|
||||
google.golang.org/protobuf v1.30.0 h1:kPPoIgf3TsEvrm0PFe15JQ+570QVxYzEvvHqChK+cng=
|
||||
google.golang.org/protobuf v1.30.0/go.mod h1:HV8QOd/L58Z+nl8r43ehVNZIU/HEI6OcFqwMG9pJV4I=
|
||||
108
2023/day2-ops-code/async/requestor/main.go
Normal file
@ -0,0 +1,108 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"database/sql"
|
||||
"errors"
|
||||
"fmt"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
nats "github.com/nats-io/nats.go"
|
||||
"time"
|
||||
)
|
||||
|
||||
func storeString(input string) error {
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
defer db.Close()
|
||||
// Insert the random number into the database
|
||||
_, err = db.Exec("INSERT INTO requestor_async(random_string) VALUES(?)", input)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
fmt.Printf("Random string %s has been inserted into the database\n", input)
|
||||
return nil
|
||||
}
|
||||
|
||||
func getStringFromDB(input string) error {
|
||||
// see if the string exists in the db, if so return nil
|
||||
// if not, return an error
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
defer db.Close()
|
||||
result, err := db.Query("SELECT * FROM requestor_async WHERE random_string = ?", input)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
for result.Next() {
|
||||
var randomString string
|
||||
err = result.Scan(&randomString)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if randomString == input {
|
||||
return nil
|
||||
}
|
||||
}
|
||||
|
||||
return errors.New("string not found")
|
||||
}
|
||||
|
||||
func main() {
|
||||
|
||||
err := createRequestordb()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
// setup a goroutine loop calling the generator every minute, saving the result in the DB
|
||||
|
||||
nc, _ := nats.Connect("nats://my-nats:4222")
|
||||
defer nc.Close()
|
||||
|
||||
ticker := time.NewTicker(60 * time.Second)
|
||||
quit := make(chan struct{})
|
||||
go func() {
|
||||
for {
|
||||
select {
|
||||
case <-ticker.C:
|
||||
nc.Publish("generator", []byte(""))
|
||||
case <-quit:
|
||||
ticker.Stop()
|
||||
return
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
nc.Subscribe("generator_reply", func(msg *nats.Msg) {
|
||||
err := storeString(string(msg.Data))
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
})
|
||||
|
||||
nc.Subscribe("confirmation", func(msg *nats.Msg) {
|
||||
err := getStringFromDB(string(msg.Data))
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
nc.Publish("confirmation_reply", []byte(string(msg.Data)))
|
||||
})
|
||||
// create a goroutine here to listen for messages on the queue to check, see if we have them
|
||||
|
||||
for {
|
||||
time.Sleep(10 * time.Second)
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
func createRequestordb() error {
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// try to create a table for us
|
||||
_, err = db.Exec("CREATE TABLE IF NOT EXISTS requestor_async(random_string VARCHAR(100))")
|
||||
|
||||
return err
|
||||
}
|
||||
2
2023/day2-ops-code/buildpush.sh
Executable file
@ -0,0 +1,2 @@
|
||||
docker build ./async/requestor/ -f async/requestor/Dockerfile -t heyal/requestor:async && docker push heyal/requestor:async
|
||||
docker build ./async/generator/ -f async/generator/Dockerfile -t heyal/generator:async&& docker push heyal/generator:async
|
||||
77
2023/day2-ops-code/database/mysql.yaml
Normal file
@ -0,0 +1,77 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: mysql
|
||||
spec:
|
||||
ports:
|
||||
- port: 3306
|
||||
selector:
|
||||
app: mysql
|
||||
clusterIP: None
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: mysql
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: mysql
|
||||
strategy:
|
||||
type: Recreate
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: mysql
|
||||
spec:
|
||||
containers:
|
||||
- image: mysql:5.6
|
||||
name: mysql
|
||||
env:
|
||||
# Use secret in real usage
|
||||
- name: MYSQL_ROOT_PASSWORD
|
||||
value: password
|
||||
- name: MYSQL_DATABASE
|
||||
value: example
|
||||
- name: MYSQL_USER
|
||||
value: example
|
||||
- name: MYSQL_PASSWORD
|
||||
value: password
|
||||
ports:
|
||||
- containerPort: 3306
|
||||
name: mysql
|
||||
volumeMounts:
|
||||
- name: mysql-persistent-storage
|
||||
mountPath: /var/lib/mysql
|
||||
volumes:
|
||||
- name: mysql-persistent-storage
|
||||
persistentVolumeClaim:
|
||||
claimName: mysql-pv-claim
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolume
|
||||
metadata:
|
||||
name: mysql-pv-volume
|
||||
labels:
|
||||
type: local
|
||||
spec:
|
||||
storageClassName: manual
|
||||
capacity:
|
||||
storage: 20Gi
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
hostPath:
|
||||
path: "/mnt/data"
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: mysql-pv-claim
|
||||
spec:
|
||||
storageClassName: manual
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
# https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/
|
||||
17
2023/day2-ops-code/synchronous/generator/Dockerfile
Normal file
@ -0,0 +1,17 @@
|
||||
# Set the base image to use
|
||||
FROM golang:1.17-alpine
|
||||
|
||||
# Set the working directory inside the container
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the source code into the container
|
||||
COPY . .
|
||||
|
||||
# Build the Go application
|
||||
RUN go build -o main .
|
||||
|
||||
# Expose the port that the application will run on
|
||||
EXPOSE 8080
|
||||
|
||||
# Define the command that will run when the container starts
|
||||
CMD ["/app/main"]
|
||||
5
2023/day2-ops-code/synchronous/generator/go.mod
Normal file
@ -0,0 +1,5 @@
|
||||
module main
|
||||
|
||||
go 1.20
|
||||
|
||||
require github.com/go-sql-driver/mysql v1.7.0
|
||||
2
2023/day2-ops-code/synchronous/generator/go.sum
Normal file
@ -0,0 +1,2 @@
|
||||
github.com/go-sql-driver/mysql v1.7.0 h1:ueSltNNllEqE3qcWBTD0iQd3IpL/6U+mJxLkazJ7YPc=
|
||||
github.com/go-sql-driver/mysql v1.7.0/go.mod h1:OXbVy3sEdcQ2Doequ6Z5BW6fXNQTmx+9S1MCJN5yJMI=
|
||||
139
2023/day2-ops-code/synchronous/generator/main.go
Normal file
@ -0,0 +1,139 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"database/sql"
|
||||
"fmt"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
"math/rand"
|
||||
"net/http"
|
||||
"time"
|
||||
)
|
||||
|
||||
func generateAndStoreString() (string, error) {
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// Generate a random string
|
||||
// Define a string of characters to use
|
||||
characters := "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
|
||||
|
||||
// Generate a random string of length 10
|
||||
randomString := make([]byte, 64)
|
||||
for i := range randomString {
|
||||
randomString[i] = characters[rand.Intn(len(characters))]
|
||||
}
|
||||
|
||||
// Insert the random number into the database
|
||||
_, err = db.Exec("INSERT INTO generator(random_string) VALUES(?)", string(randomString))
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
fmt.Printf("Random string %s has been inserted into the database\n", string(randomString))
|
||||
return string(randomString), nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
// Create a new HTTP server
|
||||
server := &http.Server{
|
||||
Addr: ":8080",
|
||||
}
|
||||
|
||||
err := createGeneratordb()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
|
||||
ticker := time.NewTicker(60 * time.Second)
|
||||
quit := make(chan struct{})
|
||||
go func() {
|
||||
for {
|
||||
select {
|
||||
case <-ticker.C:
|
||||
checkStringReceived()
|
||||
case <-quit:
|
||||
ticker.Stop()
|
||||
return
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
// Handle requests to /generate
|
||||
http.HandleFunc("/new", func(w http.ResponseWriter, r *http.Request) {
|
||||
// Generate a random number
|
||||
randomString, err := generateAndStoreString()
|
||||
if err != nil {
|
||||
http.Error(w, "unable to generate and save random string", http.StatusInternalServerError)
|
||||
return
|
||||
}
|
||||
|
||||
print(fmt.Sprintf("random string: %s", randomString))
|
||||
w.Write([]byte(randomString))
|
||||
})
|
||||
|
||||
// Start the server
|
||||
fmt.Println("Listening on port 8080")
|
||||
err = server.ListenAndServe()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
}
|
||||
|
||||
func createGeneratordb() error {
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// try to create a table for us
|
||||
_, err = db.Exec("CREATE TABLE IF NOT EXISTS generator(random_string VARCHAR(100), seen BOOLEAN)")
|
||||
|
||||
return err
|
||||
}
|
||||
|
||||
func checkStringReceived() {
|
||||
// get a list of strings from database that dont have the "seen" bool set top true
|
||||
// loop over them and make a call to the requestor's 'check' endpoint and if we get a 200 then set seen to true
|
||||
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// Insert the random number into the database
|
||||
results, err := db.Query("SELECT random_string FROM generator WHERE seen IS NOT true")
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
|
||||
// loop over results
|
||||
for results.Next() {
|
||||
var randomString string
|
||||
err = results.Scan(&randomString)
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
|
||||
// make a call to the requestor's 'check' endpoint
|
||||
// if we get a 200 then set seen to true
|
||||
r, err := http.Get("http://requestor-service:8080/check/" + randomString)
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
if r.StatusCode == 200 {
|
||||
_, err = db.Exec("UPDATE generator SET seen = true WHERE random_string = ?", randomString)
|
||||
if err != nil {
|
||||
print(err)
|
||||
}
|
||||
} else {
|
||||
fmt.Println(fmt.Sprintf("Random string has not been received by the requestor: %s", randomString))
|
||||
}
|
||||
}
|
||||
}
|
||||
69
2023/day2-ops-code/synchronous/k8s.yaml
Normal file
@ -0,0 +1,69 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: requestor
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: requestor
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: requestor
|
||||
spec:
|
||||
containers:
|
||||
- name: requestor
|
||||
image: heyal/requestor:sync
|
||||
imagePullPolicy: Always
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: requestor-service
|
||||
spec:
|
||||
selector:
|
||||
app: requestor
|
||||
ports:
|
||||
- name: http
|
||||
protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: generator
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: generator
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: generator
|
||||
spec:
|
||||
containers:
|
||||
- name: generator
|
||||
image: heyal/generator:sync
|
||||
imagePullPolicy: Always
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: generator-service
|
||||
spec:
|
||||
selector:
|
||||
app: generator
|
||||
ports:
|
||||
- name: http
|
||||
protocol: TCP
|
||||
port: 8080
|
||||
targetPort: 8080
|
||||
type: ClusterIP
|
||||
17
2023/day2-ops-code/synchronous/requestor/Dockerfile
Normal file
@ -0,0 +1,17 @@
|
||||
# Set the base image to use
|
||||
FROM golang:1.17-alpine
|
||||
|
||||
# Set the working directory inside the container
|
||||
WORKDIR /app
|
||||
|
||||
# Copy the source code into the container
|
||||
COPY . .
|
||||
|
||||
# Build the Go application
|
||||
RUN go build -o main .
|
||||
|
||||
# Expose the port that the application will run on
|
||||
EXPOSE 8080
|
||||
|
||||
# Define the command that will run when the container starts
|
||||
CMD ["/app/main"]
|
||||
5
2023/day2-ops-code/synchronous/requestor/go.mod
Normal file
@ -0,0 +1,5 @@
|
||||
module main
|
||||
|
||||
go 1.20
|
||||
|
||||
require github.com/go-sql-driver/mysql v1.7.0
|
||||
2
2023/day2-ops-code/synchronous/requestor/go.sum
Normal file
@ -0,0 +1,2 @@
|
||||
github.com/go-sql-driver/mysql v1.7.0 h1:ueSltNNllEqE3qcWBTD0iQd3IpL/6U+mJxLkazJ7YPc=
|
||||
github.com/go-sql-driver/mysql v1.7.0/go.mod h1:OXbVy3sEdcQ2Doequ6Z5BW6fXNQTmx+9S1MCJN5yJMI=
|
||||
134
2023/day2-ops-code/synchronous/requestor/main.go
Normal file
@ -0,0 +1,134 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"database/sql"
|
||||
"errors"
|
||||
"fmt"
|
||||
_ "github.com/go-sql-driver/mysql"
|
||||
"io"
|
||||
"net/http"
|
||||
"strings"
|
||||
"time"
|
||||
)
|
||||
|
||||
func storeString(input string) error {
|
||||
// Connect to the database
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
defer db.Close()
|
||||
// Insert the random number into the database
|
||||
_, err = db.Exec("INSERT INTO requestor(random_string) VALUES(?)", input)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
fmt.Printf("Random string %s has been inserted into the database\n", input)
|
||||
return nil
|
||||
}
|
||||
|
||||
func getStringFromDB(input string) error {
|
||||
// see if the string exists in the db, if so return nil
|
||||
// if not, return an error
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
defer db.Close()
|
||||
result, err := db.Query("SELECT * FROM requestor WHERE random_string = ?", input)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
for result.Next() {
|
||||
var randomString string
|
||||
err = result.Scan(&randomString)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if randomString == input {
|
||||
return nil
|
||||
}
|
||||
}
|
||||
|
||||
return errors.New("string not found")
|
||||
}
|
||||
|
||||
func getStringFromGenerator() {
|
||||
// make a request to the generator
|
||||
// save sthe string to db
|
||||
r, err := http.Get("http://generator-service:8080/new")
|
||||
if err != nil {
|
||||
fmt.Println(err)
|
||||
return
|
||||
}
|
||||
|
||||
body, err := io.ReadAll(r.Body)
|
||||
if err != nil {
|
||||
fmt.Println(err)
|
||||
return
|
||||
}
|
||||
|
||||
fmt.Println(fmt.Sprintf("body from generator: %s", string(body)))
|
||||
|
||||
storeString(string(body))
|
||||
|
||||
}
|
||||
|
||||
func main() {
|
||||
// setup a goroutine loop calling the generator every minute, saving the result in the DB
|
||||
|
||||
ticker := time.NewTicker(60 * time.Second)
|
||||
quit := make(chan struct{})
|
||||
go func() {
|
||||
for {
|
||||
select {
|
||||
case <-ticker.C:
|
||||
getStringFromGenerator()
|
||||
case <-quit:
|
||||
ticker.Stop()
|
||||
return
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
// Create a new HTTP server
|
||||
server := &http.Server{
|
||||
Addr: ":8080",
|
||||
}
|
||||
|
||||
err := createRequestordb()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
|
||||
// Handle requests to /generate
|
||||
http.HandleFunc("/check/", func(w http.ResponseWriter, r *http.Request) {
|
||||
// get the value after check from the url
|
||||
id := strings.TrimPrefix(r.URL.Path, "/check/")
|
||||
|
||||
// check if it exists in the db
|
||||
err := getStringFromDB(id)
|
||||
if err != nil {
|
||||
http.Error(w, "string not found", http.StatusNotFound)
|
||||
return
|
||||
}
|
||||
|
||||
fmt.Fprintf(w, "string found", http.StatusOK)
|
||||
})
|
||||
|
||||
// Start the server
|
||||
fmt.Println("Listening on port 8080")
|
||||
err = server.ListenAndServe()
|
||||
if err != nil {
|
||||
panic(err.Error())
|
||||
}
|
||||
}
|
||||
|
||||
func createRequestordb() error {
|
||||
db, err := sql.Open("mysql", "root:password@tcp(mysql:3306)/mysql")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer db.Close()
|
||||
|
||||
// try to create a table for us
|
||||
_, err = db.Exec("CREATE TABLE IF NOT EXISTS requestor(random_string VARCHAR(100))")
|
||||
|
||||
return err
|
||||
}
|
||||
@ -151,3 +151,5 @@ Container Image Scanning can help us find vulnerabilities in our application bas
|
||||
|
||||
Image Scanning and IAST/DAST are not mutually-exclusive.
|
||||
They both have their place in a Secure SDLC and can help us find different problems before the attackers do.
|
||||
|
||||
See you on [Day 21](day21.md).
|
||||
|
||||
@ -75,3 +75,4 @@ Another place is your container registry (as seen today).
|
||||
|
||||
Both are good options, both have their pros and cons.
|
||||
It is up to the DevSecOps architect to decide which approach works better for them and their thread model.
|
||||
See you on [Day 23](day23.md).
|
||||
|
||||
@ -159,3 +159,4 @@ A Secure SDLC would include scanning of all artifacts that end up in our product
|
||||
|
||||
Today we learned how to scan non-container artifacts like Kubernetes manifests, Helm charts and Terraform code.
|
||||
The tools we looked at are free and open-source and can be integrated into any workflow or CI pipeline.
|
||||
See you on [Day 24](day24.md).
|
||||
|
||||
@ -145,3 +145,4 @@ However, integrating signing into your workflow adds yet another layer of defenc
|
||||
Signing artifacts prevents supply-chain and man-in-the-middle attacks, by allowing you to verify the integrity of your artifacts.
|
||||
|
||||
[Sigstore](https://sigstore.dev/) and [cosign](https://docs.sigstore.dev/cosign/overview/) are useful tools to sign your artifacts and they come with many integrations to choose from.
|
||||
See you on [Day 25](day25.md).
|
||||
|
||||
@ -82,3 +82,4 @@ A scan can detect something that is vulnerability, but it cannot be actively exp
|
||||
This makes the vulnerability a low priority one, because why fix something that presents no danger to you.
|
||||
|
||||
If an issue comes up in penetration testing then that means that this issue is exploitable, and probably a high priority - in the penetation testers managed to exploit it, so will the hackers.
|
||||
See you on [Day 26](day26.md).
|
||||
|
||||
@ -127,3 +127,4 @@ More on VM security:
|
||||
<https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-security.html>
|
||||
|
||||
<https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere.security.doc/GUID-60025A18-8FCF-42D4-8E7A-BB6E14708787.html>
|
||||
See you on [Day 27](day27.md).
|
||||
|
||||
@ -82,3 +82,5 @@ That will be done by either patching up the system, closing a hole that is not n
|
||||
<https://www.comparitech.com/net-admin/free-network-vulnerability-scanners/>
|
||||
|
||||
<https://www.rapid7.com/solutions/network-vulnerability-scanner/>
|
||||
|
||||
See you on [Day 28](day28.md).
|
||||
|
||||
@ -39,7 +39,6 @@ Elaborating on this, here are the key reasons why monitoring is important for ru
|
||||
|
||||
* Gaining visibility: Monitoring provides insight into system activity, which can be used to optimize performance, troubleshoot issues, and identify opportunities for improvement.
|
||||
|
||||
|
||||
## What to monitor and record?
|
||||
|
||||
In theory, the ideal solution would be to log everything that is happening in the system and keep the data forever.
|
||||
@ -63,6 +62,7 @@ Security configurations: Monitor security configurations, such as firewall rules
|
||||
Backup and disaster recovery systems: Monitor backup and disaster recovery systems to ensure that they are operating correctly and data can be recovered in the event of a failure or disaster.
|
||||
|
||||
## A practical implementation
|
||||
|
||||
In this part, we move from theory to practice.
|
||||
|
||||
There isn't a silver bullet here, every system has its tools. We will work on Kubernetes as infrastructure with [Microservices demo](https://github.com/GoogleCloudPlatform/microservices-demo) application.
|
||||
@ -145,3 +145,4 @@ Browse Grafana for more dashboards [here](https://grafana.com/grafana/dashboards
|
||||
# Next...
|
||||
|
||||
Tomorrow we will continue to the application level. Application logs and behavior monitoring will be in focue. We will continue to use the same setup and go deeper into the rabbit hole 😄
|
||||
See you on [Day 29](day29.md).
|
||||
|
||||
@ -129,6 +129,5 @@ Now you should see Falco events in your Grafana! 😎
|
||||
|
||||
# Next...
|
||||
|
||||
Next day we will look into how to detect attacks in runtime. See you tomorrow 😃
|
||||
|
||||
|
||||
Next day we will look into how to detect attacks in runtime.
|
||||
See you tomorrow 😃 [Day 30](day30.md).
|
||||
|
||||
@ -113,4 +113,4 @@ I hope this part gave you an insight into how this system works.
|
||||
# Next
|
||||
|
||||
Tomorrow we will move away from the world of applications and go to the network layer, see you then!
|
||||
|
||||
Unto [Day 31](day31.md).
|
||||
|
||||
@ -89,3 +89,4 @@ There are several tools available to monitor network traffic in Kubernetes, each
|
||||
|
||||
These are just a few examples of the many tools available for monitoring network traffic in Kubernetes. When selecting a tool, consider the specific needs of your application and infrastructure, and choose a tool that provides the features and capabilities that best fit your requirements.
|
||||
|
||||
See you on [Day 32](day32.md).
|
||||
@ -71,6 +71,16 @@ Auditing Kubernetes configuration is simple and there are multiple tools you can
|
||||
|
||||
|
||||
We will see the simple way to scan our cluster with Kubescape:
|
||||
|
||||
```
|
||||
kubescape installation in macOs M1 and M2 chip error fixed
|
||||
|
||||
[kubescape](https://github.com/kubescape/kubescape)
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
```bash
|
||||
curl -s https://raw.githubusercontent.com/kubescape/kubescape/master/install.sh | /bin/bash
|
||||
kubescape scan --enable-host-scan --verbose
|
||||
@ -102,3 +112,5 @@ After the installation you can access the vulnerabilities via CRD with kubectl:
|
||||
kubectl get vulnerabilityreports --all-namespaces -o wide
|
||||
```
|
||||

|
||||
|
||||
[Day 33](day33.md).
|
||||
|
||||
@ -295,5 +295,4 @@ status: {}
|
||||
### Summary
|
||||
These were examples of how to turn behavior to policy! Good stuff 😃
|
||||
|
||||
|
||||
|
||||
See you on [Day 34](day34.md).
|
||||
|
||||
@ -216,4 +216,4 @@ no-privileged-containers:
|
||||
```
|
||||
|
||||
I hope this short intro gave a little taste of how admission controllers can help you to enforce runtime rules over a Kubernetes cluster!.
|
||||
|
||||
See you on [Day 35](day35.md).
|
||||
|
||||
@ -45,3 +45,5 @@ In a DevOps and automated world, secrets management solutions must be centered a
|
||||
* Azure Key Vault
|
||||
* GCP Secret Manager
|
||||
* Thycotic Secret Server
|
||||
|
||||
See you on [Day 36](day36.md).
|
||||
@ -71,3 +71,5 @@ The print argument is a string, which is one of Python's basic data types for st
|
||||
- [Learn Python - Full course by freeCodeCamp](https://youtu.be/rfscVS0vtbw)
|
||||
- [Python tutorial for beginners by Nana](https://youtu.be/t8pPdKYpowI)
|
||||
- [Python Crash Course book](https://amzn.to/40NfY45)
|
||||
|
||||
See you on [Day 43](day43.md).
|
||||
@ -111,4 +111,4 @@ try:
|
||||
|
||||
## Conclusion
|
||||
|
||||
That is it for today, I will see you tomorrow in Day 3 of Python!
|
||||
That is it for today, I will see you tomorrow in [Day 44 | Day 3 of Python!](day44.md).
|
||||
|
||||
@ -123,3 +123,4 @@ student = Student("John", "Canada", "Computer Science")
|
||||
person.speak() # "Hello, my name is Rishab and I am from Canada."
|
||||
student.speak() # "Hello, my name is John and I am a Computer Science major."
|
||||
```
|
||||
See you tomorrow in [Day 45](day45.md).
|
||||
@ -122,3 +122,6 @@ Output:
|
||||
- [pdb - The Python Debugger](https://docs.python.org/3/library/pdb.html)
|
||||
- [re - Regular expressions operations](https://docs.python.org/3/library/re.html)
|
||||
- [datetime - Basic date and time types](https://docs.python.org/3/library/datetime.html)
|
||||
|
||||
See you tomorrow in [Day 46](day46.md).
|
||||
|
||||
@ -45,3 +45,4 @@ Having a good understanding of how these web apps work, will help you with autom
|
||||
You can dive deeper into how you can build APIs using Python and serverless technologies like AWS Lambda, Azure Functions etc.
|
||||
|
||||
I have a demo on [how I built a serverless resume API](https://github.com/rishabkumar7/AzureResumeAPI).
|
||||
See you tomorrow in [Day 47](day47.md).
|
||||
|
||||
@ -60,3 +60,5 @@ In this example, we're using the Pulumi Python SDK to define an EC2 instance on
|
||||
- [Learn more about Fabric](https://docs.fabfile.org/en/stable/index.html)
|
||||
- [PyWinRM](https://github.com/diyan/pywinrm)
|
||||
- [Pulumi - IaC Tool](https://www.pulumi.com/docs/reference/pkg/python/pulumi/)
|
||||
|
||||
See you tomorrow in [Day 48](day48.md).
|
||||
|
||||
@ -153,3 +153,5 @@ Here is how it would look, I have 2 blog posts and have some gifs in my blog pos
|
||||
If we click on the `hello` blog post:
|
||||
|
||||

|
||||
|
||||
See you tomorrow in [Day 49](day49.md).
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
# Day 49: AWS Cloud Overview
|
||||
|
||||
Welcome to the AWS section of the 90 Days of DevOps! Picking 7 items to learn about is difficult for several reasons:
|
||||
|
||||
1. At last count, there were 250+ AWS services
|
||||
2. Each service could get it's own multi-day deep dive 😅
|
||||
|
||||
@ -44,3 +45,4 @@ Overall, AWS Cloud is a powerful and flexible cloud computing platform that offe
|
||||
|
||||
## Resources
|
||||
|
||||
See you tomorrow in [Day 50](day50.md).
|
||||
|
||||
@ -42,3 +42,4 @@ Once you have access to your free tier account, there are a few additional steps
|
||||
[Create your free AWS account](https://youtu.be/uZT8dA3G-S4)
|
||||
|
||||
[Generate credentials, budget, and billing alarms via CLI](https://youtu.be/OdUnNuKylHg)
|
||||
See you in [Day 52](day52.md).
|
||||
|
||||
@ -23,3 +23,5 @@ In addition to these benefits, CloudFormation also offers a range of other featu
|
||||
[AWS CloudFormation User Guide](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html)
|
||||
|
||||
[AWS CloudFormation Getting Started step-by-step guides](https://aws.amazon.com/cloudformation/getting-started/)
|
||||
|
||||
See you in [Day 52](day52.md).
|
||||
@ -54,3 +54,4 @@ After you've assigned permissions to the IAM group, you can test the IAM user to
|
||||
|
||||
[IAM Tutorial: Delegate access across AWS accounts using IAM roles](https://docs.aws.amazon.com/IAM/latest/UserGuide/tutorial_cross-account-with-roles.html)
|
||||
|
||||
See you in [Day 53](day53.md).
|
||||
|
||||
@ -47,3 +47,4 @@ Once you have created a resource group, you can view and manage your resources f
|
||||
|
||||
[Getting started with AWS System Manager](https://docs.aws.amazon.com/systems-manager/latest/userguide/getting-started-launch-managed-instance.html)
|
||||
|
||||
See you in [Day 54](day54.md).
|
||||
|
||||
@ -2,7 +2,6 @@
|
||||
|
||||

|
||||
|
||||
|
||||
AWS CodeCommit is a fully managed source control service provided by Amazon Web Services (AWS) that makes it easy for developers to host and manage private Git repositories. Think "GitHub but with less features" 🤣 (j/k, see the resource "CodeCommit vs GitHub" for a breakdown) It allows teams to collaborate on code and keep their code securely stored in the cloud, with support for secure access control, encryption, and automatic backups.
|
||||
|
||||
With AWS CodeCommit, developers can easily create, manage, and collaborate on Git repositories with powerful code review and workflow tools. It integrates seamlessly with other AWS services like AWS CodePipeline and AWS CodeBuild, making it easier to build and deploy applications in a fully automated manner.
|
||||
@ -19,8 +18,6 @@ In order to effectively leverage CodeCommit, you of course need to know how to u
|
||||
|
||||
Overall, AWS CodeCommit is a powerful tool for teams that need to collaborate on code, manage their repositories securely, and streamline their development workflows.
|
||||
|
||||
|
||||
|
||||
## Resources:
|
||||
|
||||
[AWS CodeCommit User Guide](https://docs.aws.amazon.com/codecommit/latest/userguide/welcome.html)
|
||||
@ -30,3 +27,5 @@ Overall, AWS CodeCommit is a powerful tool for teams that need to collaborate on
|
||||
[AWS CodeCommit tutorial: your first Repo, Commit and Push](https://youtu.be/t7M8pHCh5Xs)
|
||||
|
||||
[AWS CodeCommit vs GitHub: Which will Shine in 2023?](https://appwrk.com/aws-codecommit-vs-github)
|
||||
|
||||
See you in [Day 55](day55.md).
|
||||
|
||||
@ -9,6 +9,7 @@
|
||||
With CodePipeline, you can create pipelines that automate your build, test, and deployment workflows, ensuring that your code changes are reliably deployed to your target environments. It enables you to achieve faster release cycles, improve collaboration among development and operations teams, and improve the overall quality and reliability of your software releases.
|
||||
|
||||
AWS CodePipeline integrates with other AWS services:
|
||||
|
||||
- [Source Action Integrations](https://docs.aws.amazon.com/codepipeline/latest/userguide/integrations-action-type.html#integrations-source)
|
||||
- [Build Action Integrations](https://docs.aws.amazon.com/codepipeline/latest/userguide/integrations-action-type.html#integrations-build)
|
||||
- [Test Action Integrations](https://docs.aws.amazon.com/codepipeline/latest/userguide/integrations-action-type.html#integrations-test)
|
||||
@ -16,7 +17,6 @@ AWS CodePipeline integrates with other AWS services:
|
||||
- [Approval Action Integrations](https://docs.aws.amazon.com/codepipeline/latest/userguide/integrations-action-type.html#integrations-approval)
|
||||
- [Invoke Action Integrations](https://docs.aws.amazon.com/codepipeline/latest/userguide/integrations-action-type.html#integrations-invoke)
|
||||
|
||||
|
||||
It also integrates with third-party tools such as GitHub, Jenkins, and Bitbucket. You can use AWS CodePipeline to manage your application updates across multiple AWS accounts and regions.
|
||||
|
||||
## Getting started with AWS CodePipeline
|
||||
@ -36,12 +36,13 @@ To create a CodePipeline pipeline, go to the AWS CodePipeline console, click on
|
||||
Once you have created your CodePipeline pipeline, you can test and deploy your code changes. AWS CodePipeline will automatically build, test, and deploy your code changes to your target environments. You can monitor the progress of your pipeline in the AWS CodePipeline console.
|
||||
|
||||
## Capstone Project
|
||||
|
||||
To tie up this AWS section of the 90 Days of DevOps, I recommend that you go through Adrian Cantrill's excellent mini-project, the [CatPipeline](https://www.youtube.com/playlist?list=PLTk5ZYSbd9MgARTJHbAaRcGSn7EMfxRHm). In it you will be exposed to CodeCommit, CodeBuild, CodeDeploy, and CodePipeline in a fun little project that will give you a taste of a day in the life of a DevOps engineer.
|
||||
|
||||
- [YouTube CatPipeline Playlist](https://www.youtube.com/playlist?list=PLTk5ZYSbd9MgARTJHbAaRcGSn7EMfxRHm)
|
||||
- [GitHub CatPipeline Repo](https://github.com/acantril/learn-cantrill-io-labs/tree/master/aws-codepipeline-catpipeline)
|
||||
|
||||
|
||||
## Resources (Free):
|
||||
## Resources (Free)
|
||||
|
||||
[AWS: Real-world CodePipeline CI/CD Examples](https://youtu.be/MNt2HGxClZ0)
|
||||
|
||||
@ -53,10 +54,13 @@ To tie up this AWS section of the 90 Days of DevOps, I recommend that you go thr
|
||||
|
||||
[AWS CodeCommit vs GitHub: Which will Shine in 2023?](https://appwrk.com/aws-codecommit-vs-github)
|
||||
|
||||
## Resources (Paid):
|
||||
## Resources (Paid)
|
||||
|
||||
There are a number of <i>excellent</i> instructors out there and picking 2-3 is always hard, but [Adrian Cantrill](https://learn.cantrill.io/), [Andrew Brown](https://www.exampro.co/), and [Stephane Maarek](https://www.udemy.com/user/stephane-maarek/) always come to mind when discussing fantastic content out there.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
I hope that this section of the 90 Days of DevOps has given you a taste of what is available in the AWS ecosystem.
|
||||
|
||||
Good luck in your studies! Up next is Red Hat OpenShift!
|
||||
See you in [Day 56](day56.md).
|
||||
|
||||
@ -108,3 +108,4 @@ In [day 57](/day57.md) we will dive into the Architecture and components of Open
|
||||
- [OKD](https://www.okd.io/)
|
||||
- [Official Red Hat OpenShift product page](https://www.redhat.com/en/technologies/cloud-computing/openshift)
|
||||
- [Red Hat Hybrid Cloud Learning Hub](https://cloud.redhat.com/learn)
|
||||
|
||||
|
||||
@ -132,3 +132,5 @@ The great thing about databases is that there are so many choices to choose from
|
||||
Join us tommorrow when we'll be talking about querying databases.
|
||||
|
||||
Thanks for reading!
|
||||
|
||||
See you in [Day 64](day64.md).
|
||||
|
||||
@ -288,3 +288,5 @@ So that’s how to retrieve, update, and delete data from a database. We also lo
|
||||
Join us tommorrow where we will be looking at backing up and restoring databases.
|
||||
|
||||
Thank you for reading!
|
||||
|
||||
See you in [Day 65](day65.md).
|
||||
|
||||
@ -251,3 +251,5 @@ The data is back! We have successfully performed a point in time restore of our
|
||||
Join us tomorrow where we will be talking about high availability and disaster recovery.
|
||||
|
||||
Thanks for reading!
|
||||
|
||||
See you in [Day 66](day66.md).
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# High availability and disaster recovery
|
||||
|
||||
|
||||
Hello and welcome to the fourth post in the database part of the 90 Days of DevOps blog series! Today we’ll be talking about high availability and disaster recovery.
|
||||
|
||||
One of the main jobs of a database administrator is to configure and maintain disaster recovery and high availability strategies for the databases that they look after. In a nutshell they boil down to: -
|
||||
@ -207,3 +206,4 @@ Join us tomorrow where we'll be talking about performance tuning.
|
||||
|
||||
Thanks for reading!
|
||||
|
||||
See you in [Day 67](day67.md).
|
||||
|
||||
@ -136,3 +136,5 @@ And there we have it! Our query now has a supporting index!
|
||||
Join us tommorrow where we'll be talking about database security.
|
||||
|
||||
Thanks for reading!
|
||||
|
||||
See you in [Day 68](day68.md).
|
||||
@ -205,3 +205,4 @@ So if we have sensitive data within our database, this is one method of encrypti
|
||||
Join us tomorrow for the final post in the database series of 90DaysOfDevOps where we'll be talking about monitoring and troubleshooting.
|
||||
|
||||
Thanks for reading!
|
||||
See you in [Day 69](day69.md).
|
||||
|
||||
@ -162,3 +162,5 @@ Caution does need to be taken with some of these tools as they can have a negati
|
||||
So having the correct monitoring, log collection, and query tracking tools are vital when it comes to not only preventing issues from arising but allowing for quick resolution when they do occur.
|
||||
|
||||
And that’s it for the database part of the 90DaysOfDevOps blog series. We hope this has been useful…thanks for reading!
|
||||
|
||||
See you in [Day 70](day70.md).
|
||||
|
||||
@ -15,3 +15,5 @@ I am a large proponent of serverless, and I believe these are huge benefits to a
|
||||
That being said, I hope to provide you with a strong starting point for the land of serverless. Over the next few days, we will be exploring serverless resources and services, from compute, to storage, to API design, and more. We will keep our discussions high-level, but I'll be sure to include relevant examples, resources, and further reading from other leading industry experts. No prerequisites are necessary, I just ask you approach each and every article with an open mind, continue to ask questions & provide feedback, and let's dive in!*
|
||||
|
||||
*As a quick disclaimer - as I am an AWS Serverless Hero, most of the examples and explanations I give will reference the AWS ecosystem since that is where my expertise is. Many of the AWS services and tools we will discuss have equivalents across Azure, GCP, or other tooling. I will do my best to call these out going forward. This is part of a series that will be covered here, but I also encourage you to follow along on [Medium](https://kristiperreault.medium.com/what-is-serverless-1b46a5ffa7b3) or [Dev.to](https://dev.to/aws-heroes/what-is-serverless-4d4p) for more.
|
||||
|
||||
See you in [Day 71](day71.md).
|
||||
|
||||
@ -25,3 +25,5 @@ Fargate stands sort of in the middle as a container service that offers many of
|
||||
These two options pretty much sum up serverless compute, believe it or not. When it comes to your business logic code in AWS or other cloud provider, these two services cover most, if not all, serverless application needs. As we continue on in this series, you'll realize there are a ton of other 'supporting' serverless services for storage, APIs, orchestration, and more to dive into. I hope this has given you a good preview on serverless compute and what's to come, tune in tomorrow where we'll discuss the various serverless storage solutions available to us. See you then!
|
||||
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-compute-b19df2ea0935) or [Dev.to](https://dev.to/aws-heroes/serverless-compute-3bgo).
|
||||
|
||||
See you in [Day 72](day72.md).
|
||||
|
||||
@ -31,3 +31,5 @@ This is my serverless database catch-all section. In my opinion, S3 and DynamoDB
|
||||
Well, this about sums up the serverless storage solutions available. As always, there are definitely equivalents of these resources in your cloud provider of choice, and you can't go wrong with any service you choose, as long as you're evaluating based on your specific application needs. Join me tomorrow, as we take another step further into serverless with API design.*
|
||||
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-storage-4b7974683d3d) or [Dev.to](https://dev.to/aws-heroes/serverless-storage-50i3).
|
||||
|
||||
See you in [Day 73](day73.md).
|
||||
|
||||
@ -19,3 +19,5 @@ I'm keeping this section a bit shorter for you all, since [AppSync](https://aws.
|
||||
As with all of these short, daily articles, there is so much more that I could dive into here, but my purpose this week is to provide you with a little taste of what the serverless space has to offer, and get you started as a newbie to serverless. I'd highly encourage you to read up even more on [effective API Design](https://thenewstack.io/werner-vogels-6-rules-for-good-api-design/), and even get started with a tutorial, workshop, or even your own project (feel free to try out the travel website and let me know how it goes!) Believe it or not, there is still more to explore in the serverless space, so in my next post we will continue on with some really helpful integration & orchestration services.*
|
||||
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-apis-4c852f0955ef) or [Dev.to](https://dev.to/aws-heroes/serverless-apis-5bdp).
|
||||
|
||||
See you in [Day 74](day74.md).
|
||||
|
||||
@ -39,3 +39,5 @@ Similar to other services, you can define and configure your EventBridge instanc
|
||||
Although not what I would consider 'core' cloud services, the orchestration and communication services are key to event driven development and robust application design. If you are structuring your application to take advantage of event flow, these are tools you are going to want to be familiar with, and will be instrumental in your success by saving you time, money, complexity, and management overhead. This about wraps up what I want to cover with [serverless cloud services](https://aws.amazon.com/serverless/), though there is so much out there to explore. Tune in tomorrow as we start to put all of this together with best practices.*
|
||||
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-orchestration-d012aa7cae38) or [Dev.to](https://dev.to/aws-heroes/serverless-orchestration-3879).
|
||||
|
||||
See you in [Day 75](day75.md).
|
||||
@ -48,3 +48,5 @@ In addition to the six pillars, AWS Well Architected has this concept of [Well A
|
||||
|
||||
If you'd like to learn more about Well Architected or hear about it in practice, I have actually given a [recent talk on the subject with Build On at AWS Re:Invent](https://www.twitch.tv/videos/1674539542?collection=T1passDrLhdY6Q). This is an area of technology I have been very passionate about, and I truly believe these pillars and Well Architected Reviews are well worth the time and effort. We're coming up to end of our team together this week (I know, already?!) so for our last day tomorrow, I'm excited to summarize what we've learned so far, and present you with some next steps for going beyond the serverless basics.*
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-well-architected-b379d5be10ad) or [Dev.to](https://dev.to/aws-heroes/serverless-well-architected-40jn).
|
||||
|
||||
See you in [Day 76](day76.md).
|
||||
|
||||
@ -29,3 +29,5 @@ Thanks again for taking this serverless journey with me this week, and please en
|
||||
….and so much more out there for you to explore!
|
||||
|
||||
*This is part of a series that will be covered here, but I also encourage you to follow along with the rest of the series on [Medium](https://kristiperreault.medium.com/serverless-beyond-the-basics-22ba22733dd1) or [Dev.to](https://dev.to/aws-heroes/serverless-beyond-the-basics-kom).
|
||||
|
||||
See you in [Day 77](day77.md).
|
||||
|
||||
@ -66,3 +66,7 @@ Cilium is a Container Networking Interface that leverages eBPF to optimize packe
|
||||
|
||||
### Conclusion
|
||||
A serivce mesh is a power application networking layer that provides traffic management, observability, and security. We will explore more in the next 6 days of #90DayofDevOps!
|
||||
|
||||
Want to get deeper into Service Mesh? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you in [Day 78](day78.md).
|
||||
|
||||
@ -229,4 +229,6 @@ Let's label our default namespace with the *istio-injection=enabled* label. This
|
||||
### Conclusion
|
||||
I decided to jump into getting a service mesh up and online. It's easy enough if you have the right pieces in place, like a Kubernetes cluster and a load-balancer service. Using the demo profile, you can have Istiod, and the Ingress/Egress gateway deployed. Deploy a sample app with a service definition, and you can expose it via the Ingress-Gateway and route to it using a virtual service.
|
||||
|
||||
See you on Day 79 and beyond of #90DaysofServiceMesh
|
||||
Want to get deeper into Service Mesh? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you on [Day 79](day79.md) and beyond of #90DaysofServiceMesh
|
||||
|
||||
@ -66,4 +66,6 @@ Governance and Oversight | Istio Community | Linkered Community | AWS | Hashicor
|
||||
### Conclusion
|
||||
Service Meshes have come a long way in terms of capabilities and the environments they support. Istio appears to be the most feature-complete service mesh, providing a balance of platform support, customizability, extensibility, and is most production ready. Linkered trails right behind with a lighter-weight approach, and is mostly complete as a service mesh. AppMesh is mostly feature-filled but specific to the AWS Ecosystem. Consul is a great contender to Istio and Linkered. The Cilium CNI is taking the approach of using eBPF and climbing up the networking stack to address Service Mesh capabilities, but it has a lot of catching up to do.
|
||||
|
||||
See you on Day 4 of #70DaysOfServiceMesh!
|
||||
Want to get deeper into Service Mesh? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you on [Day 80](day80.md) of #70DaysOfServiceMesh!
|
||||
@ -334,4 +334,6 @@ I briefly covered several traffic management components that allow requests to f
|
||||
|
||||
And I got to show you all of this in action!
|
||||
|
||||
See you on Day 5 and beyond! :smile:!
|
||||
Want to get deeper into Service Mesh Traffic Engineering? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you on [Day 81](day81.md) and beyond! :smile:!
|
||||
|
||||
206
2023/day81.md
@ -0,0 +1,206 @@
|
||||
## Day 81 - Observability in your Mesh
|
||||
> **Tutorial**
|
||||
> *LETS see what's going on in our mesh*
|
||||
|
||||
What do you do when an application responds too slowly? Sometimes, there are network conditions well outside of our control, especially in Cloud and Data Center environments where QoS can be challenging to tune. But before we can tune up, we need to see what's up.
|
||||
|
||||
A Service Mesh provides the right key pieces to capture this data.
|
||||
The Istio Service Mesh generates a few types of telemetry and metrics to give a sense of what's happening with:
|
||||
- The control plane
|
||||
- The data plane
|
||||
- Services inside of the mesh
|
||||
|
||||
Istio provides details around:
|
||||
- Metrics for latency, errors, traffic and saturation (LETS)
|
||||
- Distributed tracing for spans to understand request flows
|
||||
- Access logs, to determine source/destination metadata of requests.
|
||||
|
||||
I have set up specific days to cover deeper observability but, let's get it going and use some tools like:
|
||||
- Prometheus
|
||||
- Grafana
|
||||
- Jaegar
|
||||
- Kiali
|
||||
|
||||
One consideration is that there are more production and enterprise-ready offerings that absolutely should be explored.
|
||||
|
||||
### Installing the sample observability addons
|
||||
I'm using the same Civo Kubernetes cluster I've been using since I started this, but I plan to create some automation to turn up and down new clusters.
|
||||
|
||||
I'm going to change back to the Istio-1.16.1 directory
|
||||
```
|
||||
cd istio-1.16.1
|
||||
```
|
||||
And then I'll deploy the sample add-ons provided in the original zip file.
|
||||
```
|
||||
kubectl apply -f samples/addons
|
||||
```
|
||||
Give it a couple of minutes and then double check.
|
||||
```
|
||||
kubectl get pods -n istio-system
|
||||
```
|
||||
```
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
istio-egressgateway-7475c75b68-mpxf7 1/1 Running 0 5d15h
|
||||
istiod-885df7bc9-f9k7c 1/1 Running 0 5d15h
|
||||
istio-ingressgateway-6688c7f65d-szxf9 1/1 Running 0 5d15h
|
||||
jaeger-54b7b57547-vsnhl 1/1 Running 0 34s
|
||||
prometheus-7b8b9dd44c-kd77d 2/2 Running 0 32s
|
||||
grafana-b854c6c8-fhjlh 1/1 Running 0 35s
|
||||
kiali-5ff88f8595-fnk8t 1/1 Running 0 33s
|
||||
```
|
||||
Perfect, let's proceed with Prometheus.
|
||||
|
||||
### Prometheus
|
||||
Since Prometheus is already installed we want to verify that it's currently running.
|
||||
|
||||
Let's check the service and verify it's online.
|
||||
```
|
||||
kubectl get svc prometheus -n istio-system
|
||||
```
|
||||
```
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
prometheus ClusterIP 10.43.234.212 <none> 9090/TCP 25h
|
||||
```
|
||||
|
||||
I'm going to generate traffic from my host to the Bookinfo app and I'll go review this in Prometheus, which we'll expose using istoctl.
|
||||
```
|
||||
curl "http://bookinfo.io/productpage"
|
||||
```
|
||||
|
||||
Let's turn up the dashboard the *istioctl dashboard [name_of_k8s_service]*:
|
||||
```
|
||||
istioctl dashboard prometheus
|
||||
```
|
||||
At this point, a web-browser (your default) should open up with Prometheus. I want to feed it a query and I will do so in the *Expression* address bar, and proceed to hit execute.
|
||||
When your browser launches with Promtheus, simply enter the following to execute a query on the total requests Istio will process.
|
||||
|
||||
Paste the below into the query bar. This query simply outputs all the requests Istio sees.
|
||||
```
|
||||
istio_requests_total
|
||||
```
|
||||

|
||||
|
||||
There's much more to what we can see in Prometheus. If you have this up in your environment, play around. I'll revisit this in later days as I intend to dig into some of the key metrcis around SLAs, SLOs, SLIs, nth-percentile and latency, requests per second and others.
|
||||
|
||||
Hit *ctrl+c* to exist the dashboard process.
|
||||
|
||||
### Grafana
|
||||
Grafana is an open-source and multi-platform analystics and visualization system that can be deployed alongside Prometheus to help us visually chart our apps and infra performance.
|
||||
|
||||
I've already installed the sample addons which contained Grafana. Let's check the services and see that it's there.
|
||||
|
||||
```
|
||||
kubectl get svc -n istio-system
|
||||
```
|
||||
And we can verify it's there.
|
||||
```
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
istiod ClusterIP 10.43.249.242 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 7d
|
||||
istio-egressgateway ClusterIP 10.43.75.47 <none> 80/TCP,443/TCP 7d
|
||||
istio-ingressgateway LoadBalancer 10.43.51.40 [HAHA.NO.NICE.TRY] 15021:31000/TCP,80:32697/TCP,443:30834/TCP,31400:30953/TCP,15443:30733/TCP 7d
|
||||
grafana ClusterIP 10.43.115.239 <none> 3000/TCP 32h
|
||||
tracing ClusterIP 10.43.237.214 <none> 80/TCP,16685/TCP 32h
|
||||
zipkin ClusterIP 10.43.241.104 <none> 9411/TCP 32h
|
||||
jaeger-collector ClusterIP 10.43.43.212 <none> 14268/TCP,14250/TCP,9411/TCP 32h
|
||||
kiali ClusterIP 10.43.51.161 <none> 20001/TCP,9090/TCP 32h
|
||||
prometheus ClusterIP 10.43.234.212 <none> 9090/TCP 32h
|
||||
```
|
||||
|
||||
Let's use the *istioctl dashboard* command again
|
||||
```
|
||||
istioctl dashboard grafana
|
||||
```
|
||||
A web browser with the Grafana tab should have opened up. On the far left, click the 4 boxes that make up a square, and then select the Istio folder.
|
||||
|
||||

|
||||
|
||||
Select the Istio Mesh Dashboard.
|
||||
|
||||
In another terminal, let's generate some load
|
||||
```
|
||||
for i in $(seq 1 100); do curl -s -o /dev/null "http://bookinfo.io/productpage"; done
|
||||
```
|
||||
The metrics for each of the services (except reviews v2) receive requests and ultimately will produce valuable metrics indicative of success, latency and other key details. We can see this below:
|
||||
|
||||

|
||||
|
||||
In the second terminal, let's generate some more load
|
||||
```
|
||||
for i in $(seq 1 300); do curl -s -o /dev/null "http://bookinfo.io/productpage"; done
|
||||
```
|
||||
|
||||
Go back to where the Istio dashboards are located, and click the Service dashboard. This will give you an idea of how the services in the mesh are performing and the client-success rate.
|
||||
|
||||

|
||||
|
||||
I'll dive more into these details in future days. Kill the dashboard by hitting *ctrl+c*
|
||||
|
||||
### Jaegar
|
||||
Jaegar is all ready to go. It's an excellent tracing tool to help piece together a trace, which is comprised of multiple spans for a given request flow.
|
||||
|
||||
Let's enable the dashboard:
|
||||
```
|
||||
istioctl dashboard jaegar
|
||||
```
|
||||
A new window should pop up with a curious-looking gopher. That gopher is inspecting stuff.
|
||||
|
||||
In our second terminal, let's issue that curl command to reach bookinfo.io.
|
||||
```
|
||||
for i in $(seq 1 300); do curl -s -o /dev/null "http://bookinfo.io/productpage"; done
|
||||
```
|
||||
In the new window with Jaeger, the left pane allows us to select a service, pick any.
|
||||
|
||||
By picking a service, you are looking from it's POV, how it's apart of the request flow. While you'll see it's span, it'll be a part of a larger trace comprised of multiple spans.
|
||||
|
||||
I picked the ratings service which shows me all the spans it's associated with in a single trace. We'll expand upon this later on.
|
||||
|
||||
All the different traces:
|
||||
|
||||

|
||||
|
||||
All the different spans within the *ratings* trace:
|
||||

|
||||
|
||||
|
||||
Ever used wireshark before?
|
||||
|
||||
Kill the jaeger dashboard with *ctrl+c*
|
||||
|
||||
### Kiali
|
||||
Kiali is another great tool to visualize how traffic and request flow inside of mesh.
|
||||
|
||||
But the visual component is captivating! It's because it shows us how one service communicates with another, using a visual map!
|
||||
|
||||
Let's enable the Kiali dashboard:
|
||||
```
|
||||
istioctl dashboard kiali
|
||||
```
|
||||
A web-browser will open with Kiali and on the left-hand pane, click on "Graph".
|
||||
|
||||
There are a few dropdowns, one says *Namespace*. Click on it and make sure the default namespace is selected. Under the *Display* dropdown, click on *Traffic Animation* and *Security*. There are other options but I'll revisit these later.
|
||||
|
||||
I'm going to open up another terminal and run this curl command:
|
||||
```
|
||||
for i in $(seq 1 300); do curl -s -o /dev/null "http://bookinfo.io/productpage"; done
|
||||
```
|
||||
|
||||
In about a few minutes you'll start to see a visual map show up in Kiali as mentioned before.
|
||||
|
||||
The screenshot below shows the directional flow of traffic, but, also notice that lock icon! It means mTLS is available. We'll explore this in the Security sections.
|
||||
|
||||

|
||||
|
||||
Finally, check out this video and see the visualization.
|
||||
|
||||

|
||||
|
||||
Or visit the video here: https://www.youtube.com/watch?v=vhV8nHgytNM
|
||||
|
||||
Go ahead and end the Kiali dashboard process with *ctrl+c*.
|
||||
|
||||
### Conclusion
|
||||
I've explored a few of the tools to be able to understand how we can observe services in our mesh and better understand how our applications are performing, or, if there are any issues.
|
||||
|
||||
Want to get deeper into Service Mesh Observability? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you on [Day 82](day82.md)
|
||||
289
2023/day82.md
@ -0,0 +1,289 @@
|
||||
## Day 82 - Securing your microservices
|
||||
> **Tutorial**
|
||||
>> *Let's secure our microservices*
|
||||
|
||||
Security is an extensive area when in comes to microservices. I could basically spend an entire 70days on just security alone but, I want to get to the specifics of testing this out in a lab environment with a Service Mesh.
|
||||
|
||||
Before I do, what security concerns am I addressing with a Service Mesh?
|
||||
- Identity
|
||||
- Policy
|
||||
- Authorization
|
||||
- Authentication
|
||||
- Encrpytion
|
||||
- Data Loss Prevention.
|
||||
|
||||
There's plenty to dig into with these but what specifically of Service Mesh helps us acheive these?
|
||||
|
||||
The sidecar, an ingress gateway, a node-level proxy, and the service mesh control plane interacting with the Kubernetes layer.
|
||||
|
||||
As a security operator, I may issue policy configurations, or authentication configurations to the Istio control plane which in turn provides this to the Kubernetes API to turn these into runtime configurations for pods and other resources.
|
||||
|
||||
In Kubernetes, the CNI layer may be able to provide a limited amount of network policy and encryption. Looking at a service mesh, encryption can be provided through mutual-TLS, or mTLS for service-to-service communication, and this same layer can provide a mechanism for Authentication using strong identities in SPIFFE ID format. Layer 7 Authorization is another capability of a service mesh. We can authorize certain services to perform actions (HTTP operations) against other services.
|
||||
|
||||
mTLS is used to authenticate peers in both directions; more on mTLS and TLS in later days.
|
||||
|
||||
To simplify this, Authentication is about having keys to unlock and enter through the door, and Authorization is about what you are allowed to do/touch, once you're in. Defence in Depth.
|
||||
|
||||
Let's review what Istio offers and proceed to configure some of this. We will explore some of these in greater detail in future days.
|
||||
|
||||
### Istio Peer Authentication and mTLS
|
||||
One of the key aspects of the Istio service mesh is its ability to issue and manage identity for workloads that are deployed into the mesh. To put it into perspective, if all services have a sidecar, and are issued an identity (it's own identity) from the Istiod control plane, a new ability to trust and verify services now exists. This is how Peer Authentication is achieved using mTLS. I plan to go into lots more details in future modules.
|
||||
|
||||
In Istio, Peer Authentication must be configured for services and can be scoped to workloads, namespaces, or the entire mesh.
|
||||
|
||||
There are three modes, I'll explain them briefly and we'll get to configuring!
|
||||
* PERMISSIVE: for when you have plaintext AND encrypted traffic. Migration-oriented
|
||||
* STRICT: Only mTLS enabled workloads
|
||||
* DISABLE: No mTLS at all.
|
||||
|
||||
We can also take care of End-user Auth using JWT (JSON Web Tokens) but I'll explore this later.
|
||||
|
||||
### Configuring Istio Peer AuthN and Strict mTLS
|
||||
Let's get to configuring our environment with Peer Authentication and verify.
|
||||
|
||||
We already have our environment ready to go so we just need to deploy another sample app that won't have the sidecar, and we also need to turn up an Authentication policy.
|
||||
|
||||
Let's deploy a new namespace called sleep and deploy a sleeper pod to it.
|
||||
```
|
||||
kubectl create ns sleep
|
||||
```
|
||||
```
|
||||
kubectl get ns
|
||||
```
|
||||
```
|
||||
cd istio-1.16.1
|
||||
kubectl apply -f samples/sleep/sleep.yaml -n sleep
|
||||
```
|
||||
|
||||
Let's test to make sure the sleeper pod can communicate with the bookinfo app!
|
||||
This command simply execs into the name of the sleep pod with the "app=sleep" label in the sleep namespace and proceeds to curl productpage in the default namespace.
|
||||
The status code should be 200!
|
||||
```
|
||||
kubectl exec "$(kubectl get pod -l app=sleep -n sleep -o jsonpath={.items..metadata.name})" -c sleep -n sleep -- curl productpage.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
```
|
||||
```
|
||||
200
|
||||
```
|
||||
|
||||
Let's apply our PeerAuthentication
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: PeerAuthentication
|
||||
metadata:
|
||||
name: "default"
|
||||
namespace: "istio-system"
|
||||
spec:
|
||||
mtls:
|
||||
mode: STRICT
|
||||
EOF
|
||||
```
|
||||
|
||||
Now, if we re-run the curl command as I did previously (I just up-arrowed but you can copy and paste from above), it will fail with exit code 56. This strongly implies that peer-authentication in STRICT mode disallows non-mTLS workloads from communicating with mTLS workloads.
|
||||
|
||||
As I mentioned previously, I'll expand further in future days.
|
||||
|
||||
### Istio Layer 7 Authorization
|
||||
Authorization is a very interesting area of security, mainly because we can granularly control who can perform whatever action against another resource. More specifically, what HTTP operations can one service perform against another. Can a service *GET* data from another service using HTTP operations?
|
||||
|
||||
I'll briefly explore a simple Authorization policy that allows GET requests but disallows DELETE requests against a resource. This is a highly granular approach to Zero-trust.
|
||||
|
||||
A consideration when moving towards production is to use a tool like Kiali (or others) to create a service mapping and understand the various HTTP calls made between services. This will allow you to establish incremental policies.
|
||||
|
||||
The one key element here is that Envoy (or Proxyv2 for Istio) as a sidecar, is the policy enforcement point for all Authorization Policies. Policies are evaluated by the authorization engine that authorizes requests at runtime. The destination sidecar, or Envoy, is responsible for evaluating this.
|
||||
|
||||
Let's get to configuring!
|
||||
|
||||
|
||||
### Configuring L7 Authorization Policies
|
||||
|
||||
In order to get a policy up and running, we first need to deny all HTTP-based based operations.
|
||||
|
||||
Also, the flow of the request looks like this:
|
||||
|
||||

|
||||
|
||||
The lock-icon is indicative of the fact that mTLS is enabled and ready to go.
|
||||
|
||||
Let's DENY ALL
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: allow-nothing
|
||||
namespace: default
|
||||
spec:
|
||||
{}
|
||||
EOF
|
||||
```
|
||||
Now if you curl bookinfo's product page from our sleep pod, it will fail!
|
||||
```
|
||||
kubectl exec "$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})" -c sleep -- curl productpage.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
```
|
||||
You'll see a 403, HTTP 403 = Forbidden...or Not Authorized
|
||||
|
||||
Here's my output:
|
||||
```
|
||||
marinow@marinos-air ~ % kubectl exec "$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})" -c sleep -- curl productpage.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
200
|
||||
```
|
||||
```
|
||||
marinow@marinos-air ~ % kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: allow-nothing
|
||||
namespace: default
|
||||
spec:
|
||||
{}
|
||||
EOF
|
||||
authorizationpolicy.security.istio.io/allow-nothing created
|
||||
```
|
||||
```
|
||||
marinow@marinos-air ~ % kubectl exec "$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})" -c sleep -- curl productpage.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
403
|
||||
marinow@marinos-air ~ %
|
||||
```
|
||||
|
||||
To fix this, we can apply a policy for each service in the request path to allow for service-to-service communication.
|
||||
|
||||
We need four authorization policies
|
||||
1. User client to product page.
|
||||
2. From Product Page to Details
|
||||
3. From product-page to reviews
|
||||
4. From reviews to ratings
|
||||
|
||||
If we look at the configuration below, the AuthZ Policy has a few key important elements:
|
||||
1. The apiVersion specifies that this is an Istio resource/CRD
|
||||
2. The spec, which states which resource will receive the HTTP Request inbound, and the method, which is GET.
|
||||
3. The action or method that can take place against the above resource, which is *ALLOW*
|
||||
|
||||
This allows an external client to run an HTTP GET operation against product-page. All other types of requests will be denied.
|
||||
Let's apply it.
|
||||
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: "get-productpage"
|
||||
namespace: default
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: productpage
|
||||
action: ALLOW
|
||||
rules:
|
||||
- to:
|
||||
- operation:
|
||||
methods: ["GET"]
|
||||
EOF
|
||||
```
|
||||
The curl command run previously should return a 200 success code.
|
||||
```
|
||||
kubectl exec "$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})" -c sleep -- curl productpage.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
```
|
||||
|
||||
But if we change the resource from productpage.default.svc.cluster.local:9080 to ratings.default.svc.cluster.local:9080, and curl to it, it should return a 403.
|
||||
```
|
||||
kubectl exec "$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})" -c sleep -- curl ratings.default.svc.cluster.local:9080 -s -o /dev/null -w "%{http_code}\n"
|
||||
```
|
||||
|
||||
We can even see the result of applying just one AuthZ policy:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
I am incrementally allowing services to trust only the services that they need to communicate with.
|
||||
|
||||
Let's apply the rest of the policies:
|
||||
|
||||
This one will allow product-page to HTTP GET details from the *reviews* service.
|
||||
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: "get-reviews"
|
||||
namespace: default
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: reviews
|
||||
action: ALLOW
|
||||
rules:
|
||||
- from:
|
||||
- source:
|
||||
principals: ["cluster.local/ns/default/sa/bookinfo-productpage"]
|
||||
to:
|
||||
- operation:
|
||||
methods: ["GET"]
|
||||
EOF
|
||||
```
|
||||
|
||||
There is a *rules* section which specifies the source of the request through the *principals* key. Here we specify the service account of the bookinfo-productpage, it's identity.
|
||||
|
||||
|
||||
|
||||
This policy allows the *reviews* services to get data from the *ratings* service
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: "get-ratings"
|
||||
namespace: default
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: ratings
|
||||
action: ALLOW
|
||||
rules:
|
||||
- from:
|
||||
- source:
|
||||
principals: ["cluster.local/ns/default/sa/bookinfo-reviews"]
|
||||
to:
|
||||
- operation:
|
||||
methods: ["GET"]
|
||||
EOF
|
||||
```
|
||||
|
||||
This policy will allow *productpage* to get details from the *details* service.
|
||||
```
|
||||
kubectl apply -f - <<EOF
|
||||
apiVersion: security.istio.io/v1beta1
|
||||
kind: AuthorizationPolicy
|
||||
metadata:
|
||||
name: "get-details"
|
||||
namespace: default
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: details
|
||||
action: ALLOW
|
||||
rules:
|
||||
- from:
|
||||
- source:
|
||||
principals: ["cluster.local/ns/default/sa/bookinfo-productpage"]
|
||||
to:
|
||||
- operation:
|
||||
methods: ["GET"]
|
||||
EOF
|
||||
```
|
||||
|
||||
If all has been deployed correctly accessing bookinfo should provide a successful result.
|
||||
|
||||
*If you've set up a local host dns record, you should be able to go to bookinfo.io/productpage to see this working*
|
||||
|
||||
Seeing this in action:
|
||||
|
||||

|
||||
|
||||
Now we know our AuthZ policies are working.
|
||||
|
||||
On Day 82 (plus several days), I dug into Authentication with mMTLS and Authorization with Authorization Policies. This just scratches the surface and we absolutely need to dig deeper. Want to get deeper into Service Mesh Security? Head over to [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh)!
|
||||
|
||||
See you on [Day 83](day83.md)
|
||||
266
2023/day83.md
@ -0,0 +1,266 @@
|
||||
## Day 83 - Sidecar or Sidecar-less? Enter Ambient Mesh
|
||||
> **Tutorial**
|
||||
>> *Let's investigate sidecar-less with Ambient Mesh*
|
||||
|
||||
### Enter Ambient Mesh
|
||||
|
||||
For Day 83 (and the final day of Service Mesh for #90DaysOfDevOps), I decided to provide some background on Istio Ambient Mesh, to provide more approaches to onboard a service mesh.
|
||||
|
||||
Istio has been around for a while and has been significantly battle-tested against various conditions, scenarios, configurations, and use-cases.
|
||||
|
||||
Design patterns have emerged where the sidecar might inhibit performance of applications and through experimentation and a constant feedback loop, Ambient Mesh was born. Ambient Mesh was a joint collaboration between [Solo.io](https://Solo.io) and Google. You can read abut the announcement [here](https://istio.io/latest/blog/2022/introducing-ambient-mesh/).
|
||||
|
||||
Ambient Mesh is still a part of Istio and as of this moment, is in Alpha under Istio 1.17. When you download istioctl, there is an Ambient Mesh profile.
|
||||
|
||||
|
||||
### The Benefits of Ambient Mesh
|
||||
|
||||
1. Reduced resource consumption: Sidecar proxies can consume a significant amount of resources, particularly in terms of memory and CPU. Eliminating the need for sidecar proxies, allows us to reduce the resource overhead associated with your service mesh.
|
||||
|
||||
2. Simplified deployment: Without sidecar proxies, the deployment process becomes more straightforward, making it easier to manage and maintain your service mesh. You no longer need to worry about injecting sidecar proxies into your application containers or maintaining their configurations.
|
||||
|
||||
3. Faster startup times: Sidecar proxies can add latency to the startup time of your services, as they need to be initialized before your applications can start processing traffic. A sidecar-less approach can help improve startup times and reduce overall latency.
|
||||
|
||||
4. Lower maintenance: Sidecar proxies require regular updates, configuration management, and maintenance. A sidecar-less approach can simplify your operational tasks and reduce the maintenance burden.
|
||||
|
||||
5. Easier experimentation: A sidecar-less approach like Ambient Mesh allows you to experiment with service mesh architectures without making significant changes to your existing applications. This lowers the barrier to entry and allows you to more easily evaluate the benefits of a service mesh.
|
||||
|
||||
6. Faster time to Zero-Trust: Ambient Mesh deploys the necessary key components to employ mTLS, Authentication, L4 Authorization and L7 Authorization
|
||||
|
||||
7. Still Istio: Istio Ambient Mesh still has all the same CRDS present like Virtual Services, Gateway, Destination Rules, Service Entries, Authentication, and Authorization Policies.
|
||||
|
||||
8. Sidecar AND Sidecarless: With Istio in Ambient mode, you can still deploy sidecars to necessary resources, and still have communication between
|
||||
|
||||
|
||||
### Ambient Mesh Architecture
|
||||
|
||||
There are several main components that drive Ambient Mesh today:
|
||||
- **Istiod**: Which is the control plane for the Istio service mesh and is the point of configuration, and certificate management.
|
||||
- **The L4 Ztunnel**: This is strictly responsible for handle mTLS for communicating pods through ztunnel pods on each node. The ztunnel pods form mTLS between each other. The ztunnel is responsible for L4 Authorization as well. This is a `daemonset` in Kubernetes.
|
||||
- **The Istio CNI Node**: Responsible for directing traffic from a workload pod to the ztunnel. This is a `daemonset` in Kubernetes.
|
||||
- **The WayPoint Proxy**: The L7 proxy which provides the same functionality as the sidecar, except deployed at the destination of a request to process things like L7 Authorization Policies. This leverages the Gateway API resource.
|
||||
- **HBONE**: The tunnel protocol which uses TCP Port 15008 to form tunnels between ztunnels on different nodes and between ztunnels and Waypoint Proxies.
|
||||
|
||||
This diagram from this [Ambient Security Blog](https://istio.io/latest/blog/2022/ambient-security/) provides a good representation of the architecture.
|
||||
|
||||
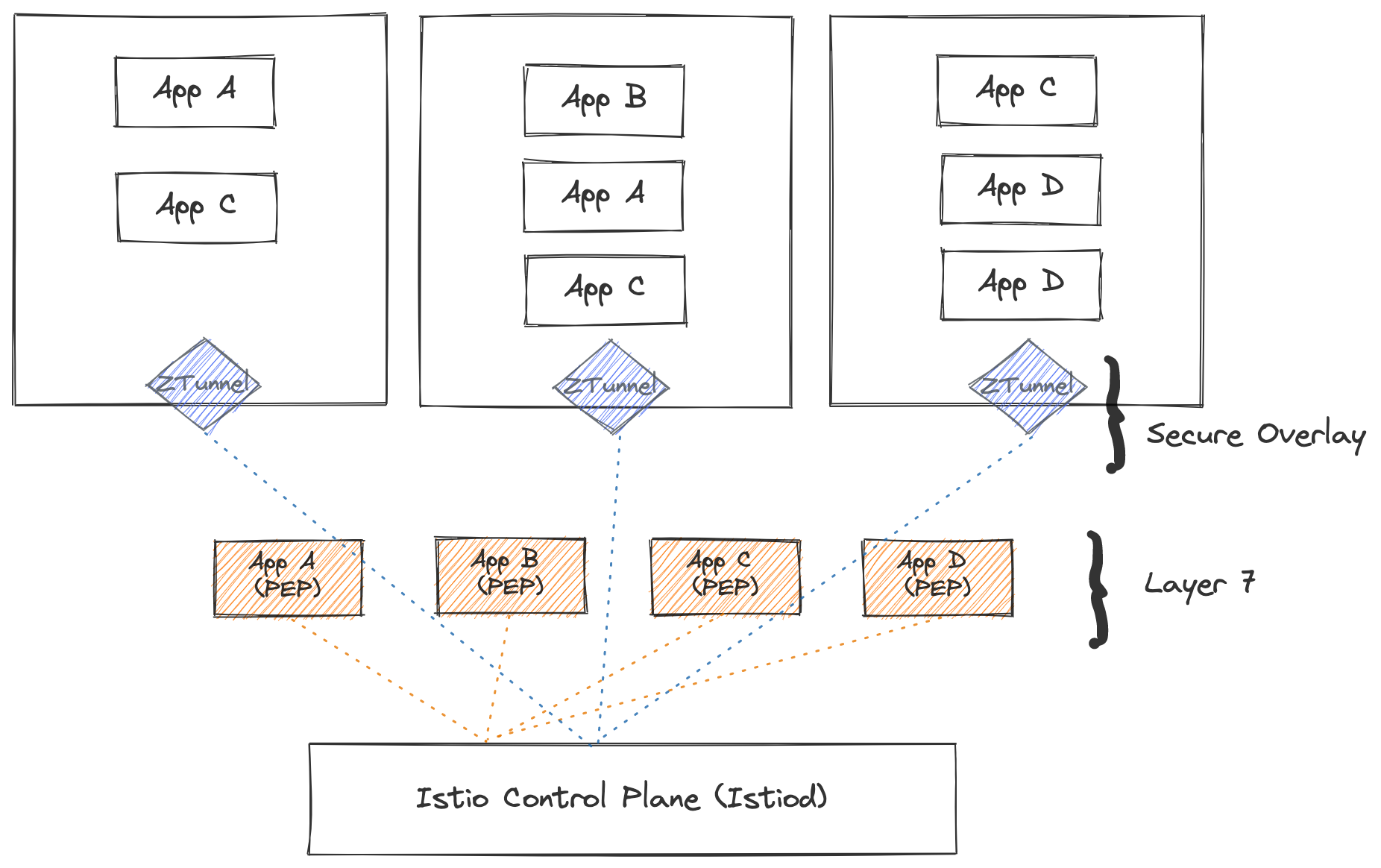
|
||||
|
||||
|
||||
|
||||
### ztunnels and Rust
|
||||
|
||||
To enhance the experience and performance of Ambient Mesh, the ztunnel which previously used a slimmed down Envoy instance, now uses Rust. Read more over at this [Rust-Based Ztunnel blog](https://istio.io/latest/blog/2023/rust-based-ztunnel/)
|
||||
|
||||
|
||||
### Deploying Ambient Mesh
|
||||
|
||||
Before we get started, you want to make sure you have a basic Kubernetes cluster. *K3s will not work today.*
|
||||
I'd recommend KinD or Minikube so you have less restrictions and the setup is pretty easy.
|
||||
|
||||
**Note** You can actually run this on ARM, or x86, so this will run well on your ARM-based MAC. In my setup i'm using x86 based Ubuntu 22.04.
|
||||
|
||||
Let's first download the binary which you can select your flavour here: https://github.com/istio/istio/releases/tag/1.18.0-alpha.0
|
||||
|
||||
```
|
||||
wget https://github.com/istio/istio/releases/download/1.18.0-alpha.0/istio-1.18.0-alpha.0-linux-amd64.tar.gz
|
||||
```
|
||||
|
||||
And then uncompress the file and change to the directory so you'll have access to the istioctl binary:
|
||||
|
||||
|
||||
```
|
||||
tar -xf istio-1.18.0-alpha.0-linux-amd64.tar.gz istio-1.18.0-alpha.0/
|
||||
```
|
||||
```
|
||||
cd istio-1.18.0-alpha.0/
|
||||
```
|
||||
|
||||
Finally, let's make istioctl executable everywhere
|
||||
```
|
||||
export PATH=$PWD/bin:$PATH
|
||||
```
|
||||
|
||||
Next, let's create your KinD cluster (assuming you already have Docker ready to go)
|
||||
```
|
||||
kind create cluster --config=- <<EOF
|
||||
kind: Cluster
|
||||
apiVersion: kind.x-k8s.io/v1alpha4
|
||||
name: ambient
|
||||
nodes:
|
||||
- role: control-plane
|
||||
- role: worker
|
||||
- role: worker
|
||||
EOF
|
||||
```
|
||||
|
||||
Which should produce the following output after completed:
|
||||
```
|
||||
Creating cluster "ambient" ...
|
||||
✓ Ensuring node image (kindest/node:v1.25.3) 🖼
|
||||
✓ Preparing nodes 📦 📦 📦
|
||||
✓ Writing configuration 📜
|
||||
✓ Starting control-plane 🕹️
|
||||
✓ Installing CNI 🔌
|
||||
✓ Installing StorageClass 💾
|
||||
✓ Joining worker nodes 🚜
|
||||
Set kubectl context to "kind-ambient"
|
||||
You can now use your cluster with:
|
||||
|
||||
kubectl cluster-info --context kind-ambient
|
||||
|
||||
Thanks for using kind! 😊
|
||||
```
|
||||
|
||||
If you'd like, feel free to verify that the cluster is there by running
|
||||
```
|
||||
kubectl get nodes -o wide
|
||||
```
|
||||
If all looks good, let's install Istio with the Ambient Profile
|
||||
```
|
||||
istioctl install --set profile=ambient --skip-confirmation
|
||||
```
|
||||
|
||||
Here is the output from my terminal assuming everything works:
|
||||
```
|
||||
marino@mwlinux02:~$ istioctl install --set profile=ambient --skip-confirmation
|
||||
✔ Istio core installed
|
||||
✔ Istiod installed
|
||||
✔ CNI installed
|
||||
✔ Ingress gateways installed
|
||||
✔ Ztunnel installed
|
||||
✔ Installation complete
|
||||
Making this installation the default for injection and validation.
|
||||
```
|
||||
|
||||
Let's verify that all the key components have been deployed:
|
||||
```
|
||||
kubectl get pods -n istio-system
|
||||
```
|
||||
And you should see:
|
||||
```
|
||||
marino@mwlinux02:~$ kubectl get pods -n istio-system
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
istio-cni-node-2wxwt 1/1 Running 0 40s
|
||||
istio-cni-node-6cptk 1/1 Running 0 40s
|
||||
istio-cni-node-khvbq 1/1 Running 0 40s
|
||||
istio-ingressgateway-cb4d6fd7-mcgtz 1/1 Running 0 40s
|
||||
istiod-7596fdbb4c-8tfz8 1/1 Running 0 46s
|
||||
ztunnel-frxrc 1/1 Running 0 47s
|
||||
ztunnel-lq4gk 1/1 Running 0 47s
|
||||
ztunnel-qbz6w 1/1 Running 0 47s
|
||||
```
|
||||
|
||||
Now, we can go ahead and deploy our app. Make sure you're still in the `istio-1.18.0-alpha.0/` directory.
|
||||
```
|
||||
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
|
||||
```
|
||||
And proceed to deploy two additional pods, `sleep` and `notsleep`
|
||||
```
|
||||
kubectl apply -f samples/sleep/sleep.yaml
|
||||
kubectl apply -f samples/sleep/notsleep.yaml
|
||||
```
|
||||
|
||||
We also need to expose our app via the Istio Ingress Gateway. Let's quickly review the file:
|
||||
```
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: bookinfo-gateway
|
||||
spec:
|
||||
# The selector matches the ingress gateway pod labels.
|
||||
# If you installed Istio using Helm following the standard documentation, this would be "istio=ingress"
|
||||
selector:
|
||||
istio: ingressgateway # use istio default controller
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
---
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: bookinfo
|
||||
spec:
|
||||
hosts:
|
||||
- "*"
|
||||
gateways:
|
||||
- bookinfo-gateway
|
||||
http:
|
||||
- match:
|
||||
- uri:
|
||||
exact: /productpage
|
||||
- uri:
|
||||
prefix: /static
|
||||
- uri:
|
||||
exact: /login
|
||||
- uri:
|
||||
exact: /logout
|
||||
- uri:
|
||||
prefix: /api/v1/products
|
||||
route:
|
||||
- destination:
|
||||
host: productpage
|
||||
port:
|
||||
number: 9080
|
||||
```
|
||||
If you need a refresher on the Gateway and Virtual Services resources, check out [Day80](day80.md)!
|
||||
|
||||
The gateway resource here is listening on *any* host, for port 80 with the HTTP protocol, and is abstracting the Istio Ingress Gateway. The Virtual Service resource is directing requests to the appropriate Kubernetes Service and its port, based on the URI path.
|
||||
|
||||
Let's apply it
|
||||
```
|
||||
kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
|
||||
```
|
||||
|
||||
Next we can test basic connectivity:
|
||||
```
|
||||
kubectl exec deploy/sleep -- curl -s http://istio-ingressgateway.istio-system/productpage | grep -o "<title>.*</title>"
|
||||
```
|
||||
```
|
||||
kubectl exec deploy/sleep -- curl -s http://productpage:9080/ | grep -o "<title>.*</title>"
|
||||
```
|
||||
```
|
||||
kubectl exec deploy/notsleep -- curl -s http://productpage:9080/ | grep -o "<title>.*</title>"
|
||||
```
|
||||
Which will all produce the result:
|
||||
```
|
||||
<title>Simple Bookstore App</title>
|
||||
```
|
||||
So we know, we can access our apps and even with Istio installed, we need to enable the Mesh. So....
|
||||
|
||||
FINALLY, we're going to throw our services into the ambient-enabled mesh, notice how we label the namespace with the `dataplane-mode=ambient` versus using the normal `istio-injection=enabled` label.
|
||||
```
|
||||
kubectl label namespace default istio.io/dataplane-mode=ambient
|
||||
```
|
||||
This label effectively tells the `ztunnel` to capture the identity of an out-bound workload and act on its behalf for mTLS, whle also telling the `istio-cni-node` pods to route traffic towards the ztunnel.
|
||||
|
||||
You can re-run the `curl` commands above if you'd like but, I'd recommend just running this looped-curl, and we can check the logs:
|
||||
```
|
||||
for i in {1..10}; do kubectl exec deploy/notsleep -- curl -s http://productpage:9080/ | grep -o "<title>.*</title>"; sleep 1; done
|
||||
```
|
||||
Now, let's review the ztunnel logs:
|
||||
```
|
||||
kubectl logs -n istio-system -l app=ztunnel
|
||||
```
|
||||
And the output:
|
||||
```
|
||||
2023-03-25T15:21:34.772090Z INFO inbound{id=50c102c520ed8af1a79e89b9dc38c4ba peer_ip=10.244.1.4 peer_id=spiffe://cluster.local/ns/default/sa/notsleep}: ztunnel::proxy::inbound: got CONNECT request to 10.244.2.8:9080
|
||||
2023-03-25T15:21:29.935241Z INFO outbound{id=a9056d62a14941a70613094ac981c5e6}: ztunnel::proxy::outbound: proxy to 10.244.2.8:9080 using HBONE via 10.244.2.8:15008 type Direct
|
||||
```
|
||||
The output is very interesting because you can see that `notsleep` is using the HBONE protocol on port `15008` to tunnel via the ztunnel over to `productpage`. If you ran `kubectl get pods -o wide` you will see that the IPs are owned by the notsleep and productpage pods. So NOW you've got a bit exposure to Ambient Mesh, go explore more!
|
||||
|
||||
|
||||
### There is so much more to Ambient Mesh
|
||||
|
||||
This module has gotten pretty long, but I encourage you to dig deeper into Ambient Mesh and see how you can potentially use it for things like Edge Computing for low-resource environments. If you want some more guided labs, check out [Solo Academy](https://academy.solo.io)!!!
|
||||
|
||||
|
||||
### The end of the Service Mesh section for #90DaysofDevOps
|
||||
|
||||
We have certainly reached the end of the Service Mesh section but, I encourage y'all to check out [#70DaysofServiceMesh](https://github.com/distributethe6ix/70DaysOfServiceMesh) to get even deeper and get ultra meshy :smile:!
|
||||
|
||||
See you on [Day 84](day84.md) and beyond! :smile:!
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
# Writing an API - What is an API?
|
||||
|
||||
The acronym API stands for “application programming interface”. What does this really mean though? It’s a way of
|
||||
controlling an application programmatically. So when you use a website that displays some data to you (like Twitter)
|
||||
there will be an action taken by the interface to get data or send data to the application (the twitter backend in this
|
||||
example) - this is done programmatically in the background by code running in the user interface.
|
||||
|
||||
In the example given above we looked at an example of a public API, however the vast majority of APIs are private, one
|
||||
request to the public twitter API will likely cause a cascade of interactions between programs in the backend. These
|
||||
could be to save the tweet text into a datastore, to update the number of likes or views a tweet has or to take an image
|
||||
that has been uploaded and resize it for a better viewing experience.
|
||||
|
||||
We build programs with APIs that other people can call so that we can expose program logic to other developers, teams
|
||||
and our customers or suppliers. They are a predefined way of sharing information. For example, we can define an API
|
||||
using [openapi specification](https://swagger.io/resources/open-api/) which is used
|
||||
for [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) API design. This api specification forms a
|
||||
contract that we can fulfil. For example, If you make an API request to me and pass a specific set of content, such as a
|
||||
date range, I will respond with a specific set of data. Therefore you can reliably expect to receive data of a certain
|
||||
type when calling my API.
|
||||
|
||||
We are going to build up an example set of applications that communicate using an API for this section of the learning
|
||||
journey to illustrate the topics and give you a hands-on look at how things can be done.
|
||||
|
||||
Design:
|
||||
2 programs that communicate bi-directionally, every minute or so one application will request a random string from the
|
||||
other, once one is received it will store this number in a database for future use
|
||||
|
||||
The Random Number generator will generate a random string when requested and save this into a database, the application
|
||||
will then ask the first program for confirmation that it received the string, and store this information against the
|
||||
string in the database
|
||||
|
||||
The applications will be called:
|
||||
generator
|
||||
requestor
|
||||
|
||||
This may sound like a silly example but it allows us to quickly look into the various tasks involved with building,
|
||||
deploying, monitoring and owning a service that runs in production. There are bi-directional failure modes as each
|
||||
application needs something from the other to complete successfully and things we can monitor such as API call rates -
|
||||
We can see if one application stops running.
|
||||
|
||||
We need to now decide what our API Interfaces should look like. We have 2 API calls that will be used to communicate
|
||||
here. Firstly, the `requestor` will call the `generator` and ask for a string. This is likely going to be an API call
|
||||
without any additional content other than making a request for a string. Secondly, the `generator` will start to ask
|
||||
the `requestor` for confirmation that it received and stored the string, in this case we need to pass a parameter to
|
||||
the `requestor` which will be the string we are interested in knowing about.
|
||||
|
||||
The `generator` will use a URL path of `/new` to serve up random strings
|
||||
The `requestor` is going to use URL paths to receive string information from the `generator` to check the status, so we
|
||||
will setup a URL of `/strings/<STRING>` where <STRING> is the string of interest.
|
||||
|
||||
|
||||
## Building the API
|
||||
There is a folder on the Github repository under the 2023 section called `day2-ops-code` and we will be using this
|
||||
folder to store our code for this, and future, section of the learning journey.
|
||||
|
||||
We are using Golang's built in HTTP server to serve up our endpoints and asynchronous goroutines to handle the
|
||||
checks. Every 60 seconds we will look into the generators database and get all the strings which we dont have
|
||||
conformation for and then calling the requesters endpoint to check if the string is there.
|
||||
@ -0,0 +1,62 @@
|
||||
# Queues, Queue workers and Tasks (Asynchronous architecture)
|
||||
Yesterday we looked at how we can use HTTP based APIs for communication between services. This works well until you need
|
||||
to scale, release a new version or one of your services goes down. Then we start to see the calling service fail because
|
||||
it’s dependency is not working as expected. We have tightly coupled our two services, one can’t work without the other.
|
||||
|
||||
There are many ways to solve this problem, a light touch approach for existing applications is to use something called a
|
||||
circuit breaker to buffer failures and retry until we get a successful response. This is explained well in this blog
|
||||
by [Martin Fowler](https://martinfowler.com/bliki/CircuitBreaker.html). However, this is synchronous, if we were to wrap
|
||||
our calls in a circuit breaker we would start to block processes and our user could see a slowdown in response times.
|
||||
|
||||
Additionally, we can’t scale our applications using this approach, the way that the code is currently written every
|
||||
instance of our `generator` api would be asking
|
||||
the `requestor for confirmation of receiving the string. This won’t scale well when we move to having 2, 5, 10, or 100 instances running. We would quickly see the `
|
||||
requestor` being overwhelmed with requests from the 100 generator applications.
|
||||
|
||||
There is a way to solve these problems which is to use Queues. This is a shift in thinking to using an asynchronous
|
||||
approach to solving our problem. This can work well when the responses don’t need to be immediate between applications.
|
||||
In this case it doesn't matter if we add some delay in the requests between the applications. As long as the data
|
||||
eventually flows between them we are happy.
|
||||
|
||||

|
||||
(https://dashbird.io/knowledge-base/well-architected/queue-and-asynchronous-processing/)
|
||||
|
||||
In the drawing above we can see how we can add a Queue in between our applications and the Queue stores the intent of
|
||||
the message across the bridge. If the Consumer was to fail and stop reacting messages then, providing our Queue software
|
||||
has sufficient storage, the messages to the consumer would still “succeed” as far as the producer is concerned.
|
||||
|
||||
This is a powerful pattern that isolates components of a system from each other and limits the blast radius of failure.
|
||||
It does however add complexity. The Consumer and Producer must share a common understanding of the shape of a message
|
||||
otherwise the Consumer will be unable to act on the message.
|
||||
|
||||
We are going to implement a Queue in between our two applications in our data flows.
|
||||
|
||||
By the end of the section we will have the following data flows
|
||||
|
||||
Requestor (asks for a random string) → Queue → Generator (gets the message, generates a string and passes it back to the
|
||||
Requestor on another Queue) → Requestor (gets the string back on a queue and stores it, then sends a message to the
|
||||
queue saying it has received it) → Queue → Generator (marks that the message was received)
|
||||
|
||||
The last section here, where the Generator needs to know if the Requestor got the message is a simplification of a real
|
||||
process where an application may pass back an enriched data record or some further information but it allows us to have
|
||||
a simple two way communication.
|
||||
|
||||
Can you see how by the end of this section we will be able to stop, scale, deploy or modify each of the two components
|
||||
without the other needing to know?
|
||||
|
||||
## Modifying our application
|
||||
|
||||
We are now going to modify our app to fit the model described above. Where we previously made a HTTP api call to our
|
||||
partner app we are now going to place a message on a named queue and then subscribe to the corresponding response
|
||||
queues.
|
||||
|
||||
Finally we are going to stop using HTTP endpoints to listen for requests, we are now subscribing to queues and waiting
|
||||
for messages before we perform any work.
|
||||
|
||||
I have picked [NATSio](https://nats.io/) as the queue technology as I have worked with it previously and it’s very easy
|
||||
to set up and use.
|
||||
|
||||
Head over to the 2023/day2-ops-code/README.md to see how to deploy day 2's application.
|
||||
|
||||
It sends messages to a queue and then waits for a response. The response is a message on a different queue. The message
|
||||
contains the data that we are interested in.
|
||||
@ -0,0 +1,95 @@
|
||||
# Designing for Resilience, Redundancy and Reliability
|
||||
|
||||
We now have an application which uses asynchronous queue based messaging to communicate. This gives us some real
|
||||
flexibility on how we design our system to withstand failures. We are going to look at the concept of Failure Zones,
|
||||
Replication, Contract testing, Logging and Tracing to build more robust systems.
|
||||
|
||||
## Failure Zones
|
||||
|
||||
Imagine building an application and deploying everything onto a single VM or server. What happens when, inevitably, this
|
||||
server fails. Your application goes offline and your customers won’t be happy! There’s a fix to this. Spread your
|
||||
workloads over multiple points of failure. This doesn’t just go for your application instances but you can build
|
||||
multiple redundant points for every aspect of your system.
|
||||
|
||||
Ever wonder what some of the things large cloud providers do to keep their services running despite external and
|
||||
unpredictable factors? For starters they will have generators on-site for when they inevitably suffer a power cut. They
|
||||
have at least two internet connections into the datacentres and they often provide multiple availability zones in each
|
||||
region. Take Amazon’s eu-west-2 (London) region. This has 3 availability zones, eu-west-2a, eu-west-2b and eu-west-2c.
|
||||
There are 3 separate datacenters (physically separated) that all inter-connect to provide a single region. This means by
|
||||
deploying services across these availability zones (AZs) we increase our redundancy and resilience over factors such as
|
||||
a fire in one of these facilities. If you run a homelab you could distribute work over failure zones by running more
|
||||
than one computer, placing these computers in separate parts of the house or buying 2 internet connections to stay
|
||||
online if one goes down (This does mean checking that these connections don’t just run on the same infrastructure as
|
||||
soon as they leave your door. At my house I can get fibre to my house and also a connection over the old phone lines)
|
||||
|
||||
## Replication
|
||||
|
||||
This links nicely into having multiple replicas of our “stuff”, this doesn’t just mean running 2 or 3 copies of our
|
||||
application over our previously mentioned availability zones we also need to consider our data - If we ran a database in
|
||||
AZ1 and our application code over AZ1, AZ2 and AZ3 what do you think would happen if AZ1 was to go offline, potentially
|
||||
permanently? There have been instances of cloud datacenters being completely destroyed by fire and many customers had
|
||||
not been backing up their data or running across multiple AZs. Your data in this case is… gone. Do you think the
|
||||
business you workin in could survive if their data, or their customers data, just disappeared overnight?
|
||||
|
||||
Many of our data storage tools come with the ability to be configured for replication across multiple failure zones.
|
||||
NATS.io that we used previously can be configured to replicate messages across multiple instances to survive failure of
|
||||
one or more zones. Postgresql databases can be configured to stream their WAL (Write ahead log), which stores an
|
||||
in-order history of all the transactions, to a standby instance running somewhere else. If our primary fails then the
|
||||
most we would lose would be the amount of data in our WAL that was not transferred to the replica. Much less data loss
|
||||
than if we didn’t have any replication.
|
||||
|
||||
## Contract Testing
|
||||
|
||||
We are going to change direction now and look at making our applications more reliable. This means reducing the change
|
||||
of failures. You may appreciate that the time most likely to cause failures in your system is during deployments. New
|
||||
code hits our system and if it has not been tested thoroughly in production-like environments then we may end up with
|
||||
undefined behaviours.
|
||||
|
||||
There’s a concept called Contract testing where we can test the interfaces between our applications at development and
|
||||
build time. This allows us to rapidly get feedback (a core principle of DevOps) on our progress.
|
||||
|
||||
## Async programming and queues
|
||||
|
||||
We have already discussed how breaking the dependencies without our system can lead to increased reliability. Our
|
||||
changes become smaller, less likely to impact other areas of our application and easy to roll-back.
|
||||
|
||||
If our users are not expecting an immediate tactile response to an event, such as requesting a PDF be generated then we
|
||||
can always place a message onto a queue and just wait for the consumer of that message to eventually get round to it. We
|
||||
could see a situation where thousands of people request their PDF at once and an application that does this
|
||||
synchronously would just fall over, run out of memory and collapse. This would leave all our customers without their
|
||||
PDFs and needing to take an action again to wait for them to be generated. Without developer intervention we may not get
|
||||
back to a state where the service can recover.
|
||||
|
||||
Using a queue we can slowly work away in the background to generate these PDFs and could even scale the service in the
|
||||
background automatically when we noticed the queue getting longer. Each new application would just take the next message
|
||||
from the queue and work through the backlog. Once we were seeing less demand we could automatically scale these services
|
||||
down when our queue depth reached 0.
|
||||
|
||||
## Logging and Tracing
|
||||
|
||||
It goes without saying that our applications and systems will fail. What we are doing in this section of 90daysOfDevOps
|
||||
is thinking about what we can do to make our lives less bad when things do. Logging and tracing are some really
|
||||
important tools in our toolbox to keep ourselves happy.
|
||||
|
||||
If we log frequently with both success and failure messages we can follow the progress of our requests and customer
|
||||
journeys through our system then when things go wrong we can quickly rule out specific services or focus down on
|
||||
applications that are logging warning or error messages. My general rule is that you can’t log too much - its not
|
||||
possible! It is however important to use a log framework that lets you tune the log level that gets printed to your
|
||||
logs. For example if i have 5 log levels (as is common), TRACE, DEBUG, INFO, WARN and ERROR we should have a mechanism
|
||||
for ever application to set the level of logs we want to print. Most of the time we only want WARN and ERROR to be
|
||||
visible in logs, to quickly show us theres and issue. However if we are in development or debugging a specific
|
||||
application its important to be able to turn up the verbosity of our logs and see those INFO/DEBUG or TRACE levels.
|
||||
|
||||
Tracing is a concept of being able to attack a unique identifier to a request in our system that then gets populated and
|
||||
logged throughout that requests journey, we could see a HTTP request hit a LoadBalancer, get a correlationID and then we
|
||||
want to see that correlationID in ever log line as our request’s actions percolate through our system.
|
||||
|
||||
## Conclusion
|
||||
|
||||
It’s hard to build a fully fault-tolerant system. It involves learning from our, and other people’s, mistakes. I have
|
||||
personally made many changes to company infrastructure after we discovered a previously unknown failure zone in our
|
||||
application.
|
||||
|
||||
We could change our application running in Kubernetes to tolerate our underlying infrastructure’s failure zones by
|
||||
leveraging [topology spread constraints](https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/)
|
||||
to spread replicas around. We won’t in this example as we have much more to cover!
|
||||
BIN
2023/images/Day81-1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 630 KiB |
BIN
2023/images/Day81-2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 109 KiB |
BIN
2023/images/Day81-3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 499 KiB |
BIN
2023/images/Day81-4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 375 KiB |
BIN
2023/images/Day81-5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 350 KiB |
BIN
2023/images/Day81-6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 338 KiB |
BIN
2023/images/Day81-7.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 166 KiB |
BIN
2023/images/Day81-8.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.3 MiB |
BIN
2023/images/Day82-1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 137 KiB |
BIN
2023/images/Day82-2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 66 KiB |
BIN
2023/images/Day82-3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 108 KiB |
BIN
2023/images/day84-queues.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 34 KiB |